The Magical Number Seven
- Published on
- ∘ 39 min read ∘ ––– views
Tags
Previous Article
"My problem is that I have been persecuted by an integer": Introduction
I have the number 7 tattooed on my wrist. When she first noticed, my mother asked what it meant. At the time, I didn't have the snide articulation of the author of this week's paper:
Perhaps there is something deep and profound behind [the number seven], something just calling out for us to discover it.
"The Magical Number Seven, Plus or Minus Two: Some Limits on our Capacity for Processing Information" was introduced to me courtesy of Kit Langton from Zio in the context of the benefits of functional programming over conventional, imperative programming paradigms. This article in the Psychological Review focuses on our cognitive capacity and ability to differentiate between multiple phonemes of stimuli at once.
Throughout the paper, Miller –the author– poses several open questions he hopes to see fleshed out with other experimental results. And, having the benefit of 55-odd years of academic advantage over Miller, I was hoping to plug in some of the gaps with more recent developments. However, to my dismay, I found that many of these questions remained unanswered:
How did it come about that a widely-cited work on a subject of fundamental and obvious interest could halt some areas of research rather than inspire them? I would argue that the famous article of George Miller (1956) on "the magical number seven plus or minus two" did just that. It was followed by a 40-year hiatus of work on the topic of item capacity limits in working memory. It seems a paradox for such a widely cited and esteemed source to inspire little closely-related follow-up work for such a long period. 1
While I'm sure that there do exist numerous ""building blocks,"" (some of which I do make reference to later on),2 I mostly gave up on this endeavor – Miller offered enough insight for me.
The paper opens with a rather humorous tirade about the Miller's consternation caused by the number seven, as well as what I have to assume is a tongue-in-cheek paraphrasal of Joseph McCarthy? It's worth repeating in full here if only as a enticing snippet to motivate you to read the whole thing yourself.
My problem is that I have been persecuted by an integer. For seven years this number has followed me around, has intruded in my most private data, and has assaulted me from the pages of our most public journals. This number assumes a variety of disguises, being sometimes a little larger and sometimes a little smaller than usual, but never changing so much as to be unrecognizable. The persistence with which this number plagues me is far more than a random accident. There is, to quote a famous senator, a design behind it, some pattern governing its appearances. Either there really is something unusual about the number or else I am suffering from delusions of persecution.
"Now just a brief word about the bit": Miller's Theory of Information
Writing less than a decade after Shannon published A Mathematical Theory of Communication, the harbinging text on information theory, Miller's subject of concern is similar to Shannon's notion of Entropy, that is– the measure of the amount of information.
He draws similarities between Entropy, and Variance claiming that "anything that increases variance also increases the amount of information" of a statistic. "When we have a large variance, we are very ignorant about what is going to happen. If we are very ignorant, then when we make the observation it gives us a lot of information. On the other hand, if the variance is very small, we know in advance how our observation must come out, so we get little information from making the observation."
Mathematically, Shannon expresses this notion of information as surprise as:
Of particular interest to the experimental settings which Miller summarizes in this paper which is also intrinsic to Information Theory are the channels of communication used between experimental subjects and researchers.
Input and output to a system can therefore be described in terms of their variance (or information).
Good communication systems have a high correlation between what goes in and what comes out. "If we measure this correlation, we can say how much of the output variance is attributable to the input, and how much is due to random fluctuations or noise." Thus, the measure of transmitted information is simply a measure of the correlation between the input and output.
- Variance: the amount of information
- Covariance: the amount of transmitted information
As a model for such a system of communication, Miller offers a venn diagram of sorts representing experiments in absolute judgement, the observer represents the communication channel. The left circle of the venn diagram represents the variance of the input, the right circle the variance of the output, and therefore, their overlap is the amount of transmitted information. The ideal, then, is a concentric circle.

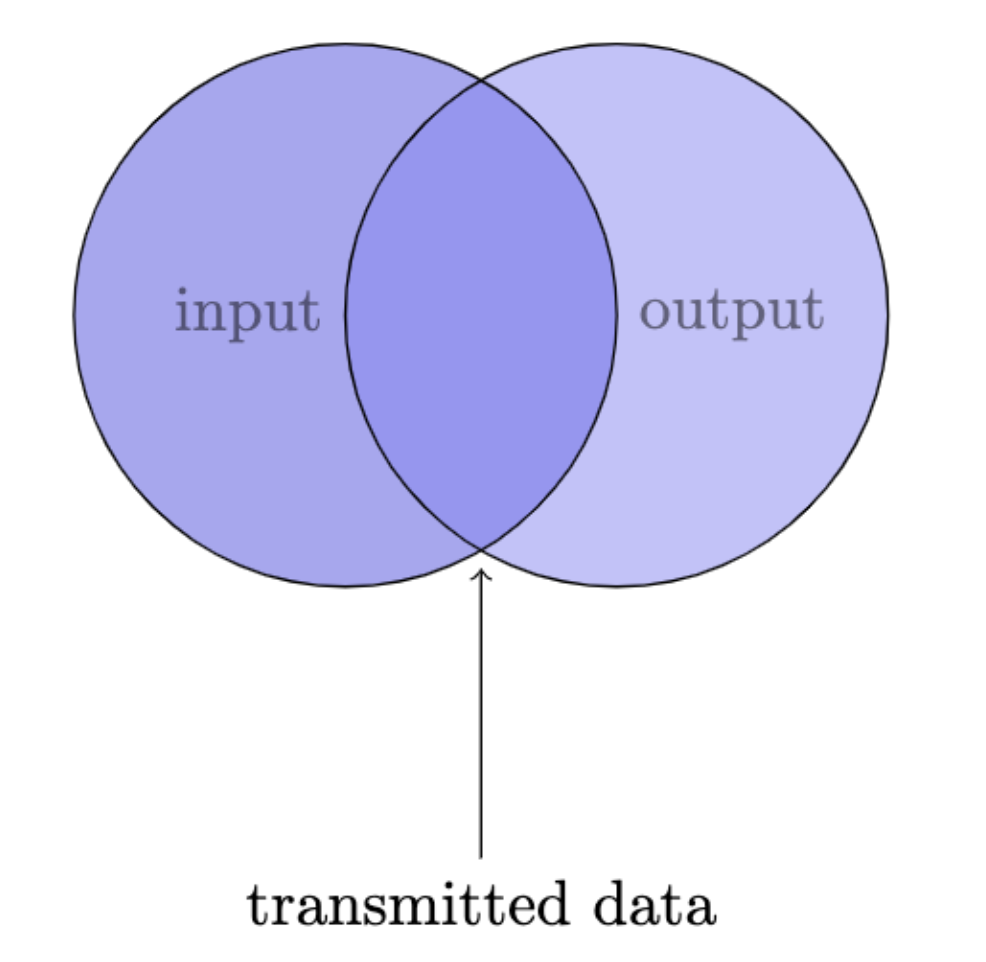
That is rarely the case in practice though, and so the experimental problem at hand is to increase the amount of input information and to measure the amount of transmitted information under the hypothesis that increases in input information will translate to an increase in transmitted information up to some asymptotic threshold after which the transmitted information will taper off. This threshold is the channel capacity of the observer. For all intents and purposes, this can be understood to be the memory or quantitative cognitive limits of a human observer.
This is the essence of the "problem" with the human brain. We are the observer with impaired judgment abilities for selection problems involving more than just a handful of options.
The unit of measurement of information is the bit which is defined as the amount of information that we need to make a decision between two equally likely alternatives. The bit itself is unit-agnostic, meaning that if we must decide whether a person is taller or shorter than 6' with equal probability, one bit of information is all we need to make a decision, and the bit of information itself makes no reference to any unit of length.
In this example, one bit of information allows us to make a binary decision: the person is either taller or shorter than 6 feet tall. With two bits of information, we can make informed decisions between 4 equally likely decisions; 3 bits enables decisions among 8 alternatives, and so on. So we can say that the value of a bit of information scales exponentially in terms of the amount of alternatives we can discriminate between at once.
Formally, for a set of equally likely alternatives , the number of bits needed to decide between them is given by:
Or, flipping the implied-but-not-actual causality of this relationship around: whenever the number of alternatives is increased by a factor of two, one bit of information is added.
Naturally, the ulterior goal behind measurement of information is increasing the throughput of our communication system. Miller highlights two ways we might achieve this:
- Increase the rate at which we give information to the observer
- Ignore the time variable completely, and increase the number of alternative stimuli.
In the absolute judgement scenario, we are interested in the latter means of information augmentation, giving the observer as much time as needed, increasing the number of alternatives she must discriminate between, and finding that asymptotic threshold at which point confusions begin to occur. This point is referred to as the channel capacity.
"Now Let us See Where We Are": Unidimensional Experimental Results
To measure the efficacy of increasing stimuli, Miller recapitulates the findings of several other related efforts to measure how many things a test subject can juggle in their mind at once.
The first set of experiments involve uni-dimensional stimuli - meaning that the alternatives all fall along the same axis, offering only lateral comparisons between phonemes.
The first experiment required listeners to identify tones played at different frequencies, with the test subjects being asked to respond to sounds with a number corresponding to the rank of the tone in given set of alternatives, and afterwords being told the correct index.
When only two or three tones were used the listeners never confused them. With four different tones confusions were quite rare, but with five or more tones confusions were frequent. With fourteen different tones the listeners made many mistakes.

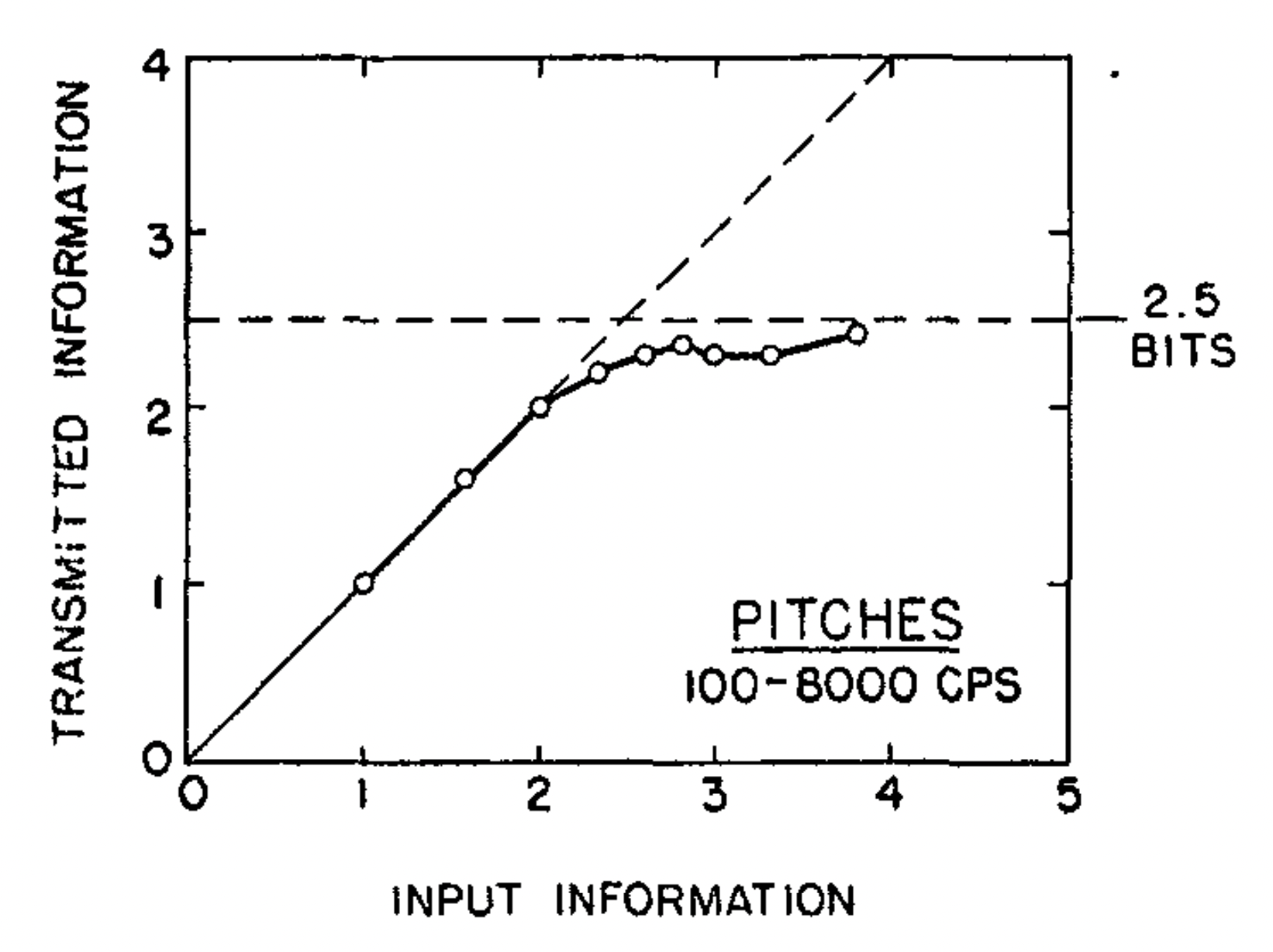
the amount of transmitted information behaves in much the way we would expect a communication channel to behave; the transmitted information increases linearly up to about 2 bits and then bends off toward an asymptote at about 2.5 bits. This value of 2.5 bits, therefore, is what we are calling the channel capacity of the listener for absolute judgements of pitch
2.5 bits corresponds to about six equally likely alternatives, meaning that we cannot pick more than six different pitches that the listener will never confuse. Or, stated slightly differently, no matter how many alternative tones we ask him to judge, the best we can expect him to do is to assign them to about six different classes without error. Or again, if we know that there were alternative stimuli, then his judgements enable us to narrow down the particular stimulus to one out of
Miller points out that these results in particular might be skewed by those gifted with perfect pitch, but dismisses them saying:
Fortunately, I do not have time to discuss these remarkable exceptions. I say it is fortunate because I do not know how to explain their superior dominance.
King shit.
In another experiment which modulated loudness rather than pitch, Miller notes that though we would expect a subject who can differentiate between five high-pitched tones in ones series, and five low-pitched in another series, to be able to combine the two series to one single series of 10 tones, differentiable without error, we would be mistaken! The channel capacity for pitch seems to be about six, and that's the best you can do. Therefore, information does not indefinitely scale linearly, nor even logarithmically.
Miller summarizes the findings of several other, similar experiments in measuring cognitive capacity, offering commentary on why the various mediums of differentiation might vary, but also pointing out that they don't vary much.
| Researcher | Alternatives | Channel Capacity (bits) | Alternatives |
|---|---|---|---|
| Pollack | Pitch | 2.5 | 6 |
| Garner | Loudness | 2.3 | 5 |
| Rogers & O'Connell | Flavor Intensity | 1.9 | 4 |
| Hake & Garner | Points on a Line3 | 3.25 | 10 |
| Coonan & Klemmer | Points on a Line | 3.2 - 3.9 | 10 - 15 |
| Eriksen & Hake | Size of a square | 2.2 | 5 |
| Eriksen | Size | 2.8 | 7 |
| Eriksen | Hue | 3.1 | 9 |
| Eriksen | Brightness | 2.3 | 5 |
| Airforce Operational Application Lab | Area (short exposure) | 2.6 | 6 |
| Airforce Operational Application Lab | Area (long exposure) | 2.7 | 6 |
| Airforce Operational Application Lab | Length (short) | 2.6 | 6 |
| Airforce Operational Application Lab | Length (long) | 3.0 | 8 |
| Airforce Operational Application Lab | Angle of inclination (short) | 2.8 | 7 |
| Airforce Operational Application Lab | Angle of inclination (long) | 3.3 | 10 |
| Airforce Operational Application Lab | Curvature (short) | 1.6 | 3 |
| Airforce Operational Application Lab | Curvature (long) | 2.2 | 5 |
While some categories of unidimensional stimuli seemed less distinctive than others, the order of magnitude was about the same. Sight appeared to be the best channel of observation, followed by auditory, then taste. Broadly speaking, this table shows that the Information Theoretic notion of channel capacity appears to be a valid measurement for describing human observation.
Channel capacities for unidimensional stimuli ranged from 1.6 to 3.9 bits for curvature and positions on the interval respectively. The average capacity across each of these categories is 2.6 bits with bits, corresponding to about 6.5 alternatives in a unidimensional category, banded on 4 to 10 categories by one standard deviation, on a complete range of 3 to 15 alternatives, which Miller highlights as being remarkably narrow. Rounding up, we get 7 ± 2 as the magical number of things that we can keep straight in our minds simultaneously, regardless of what they are.
Miller asserts that this limitation of cognitive capacity can be attributed to the evolution of our nervous systems. Organisms that were the most successful were those that were responsive to the widest range of stimulus energies in their environment. In order to survive in a constantly fluctuating world, it was better to have a little information about a lot of things that to have a lot of information about a small segment of the information
Absolute Judgements of Multi-Dimensional Stimuli
At first it seems as though the above results conflict with our intuition and experience in the mundane to accurately identify any one of several hundred faces, words, objects, etc. in our everyday sufferings of the human condition. The explanation explored by Miller is that each observable attribute in an alternative adds a dimension by which we can distinguish and "cross examine" stimuli.
Faces, words, and objects differ from on another in many ways, whereas the simple stimuli considered thus far differ from one another in only one respect.
Experiments in discrimination along multiple axes revealed much stronger degrees of cognitive differentiation. The simplest example being the selection of positions. Instead of restricting the domain to an interval or line, Klemmer and Frick iterated on the one-dimensional experiment by asking subjects to place a dot within a square. In this case, the channel capacity increases to 4.6 bits, corresponding to accurate identification of any one of 24 positions in the square.
The position of a dot in a square is clearly a two-dimensional proposition. Both its horizontal and vertical position must be identified. Thus it seems natural to compare the 4.6 bit capacity for a square with the 3.25 bit capacity for the position of a point in an interval. The point in the square requires two judgement of the interval type.
In this experimental setting, the brain is "triangulating" the position of the point. However, as Miller points out, the linear increase in input information does not translate to a linear increase of transmitted information.
If we have a capacity of 3.25 bits for estimating intervals and we do this twice, we should get 6.5 bits as our capacity for locating points in a square. Adding the second independent dimension gives us an increase for 3.25 to 4.6 bits, but it falls short of the perfect addition that would give 6.5 bits.
This observation that information value does not compound linearly was reinforced by other experimental results in multiple dimensions:
| Researcher | Alternatives | Channel Capacity (bits) | Alternatives |
|---|---|---|---|
| Klemmer & Frick | Points in the square | 4.6 | 24 |
| Rogers & O'Connell | Saltiness and Sweetness | 2.3 | 5 |
| Pollack | Loudness and Pitch | 3.1 | 9 |
| Halsey & Chapanis | Hue and Saturation | 3.6 | 11 - 15 |
| Halsey & Chapanis | Hue and Saturation | 3.6 | 11 - 15 |
In each case, comparisons can be made between the expected result given from the addition of the two unidimensional experiments and the actual output which consistently fell short of the linear combination of the constituent stimuli.
Research involving even more dimensions was limited, but Pollack and Ficks managed to get six different acoustic variables that could be modulated across 5 distinct values, theoretically yielding representable tones. Listeners made a separate rating for each one of the six dimensions resulting in 7.2 bits or 150 different categories identified without error which is on the order of the range that ordinary experience would lead us to expect.
Clearly, the addition of independently variable attributes to the stimulus increases the channel capacity, but at a decreasing rate. It is interesting to note that the channel capacity is increased even when the several variables are not independent.
Eriksen's experimental results confounding hue, saturation, and size varied together in perfect correlationspelling resulted in a 4.1 bis of transmitted information which is an increase over the 2.7 bits when these attributes were varied one at a time.
By confounding three attributes, Eriksen increased the dimensionality of the input without increasing the amount of input information; the result was an increase in channel capacity of about the amount that the dotted function in Fig. 6 would lead us to expect
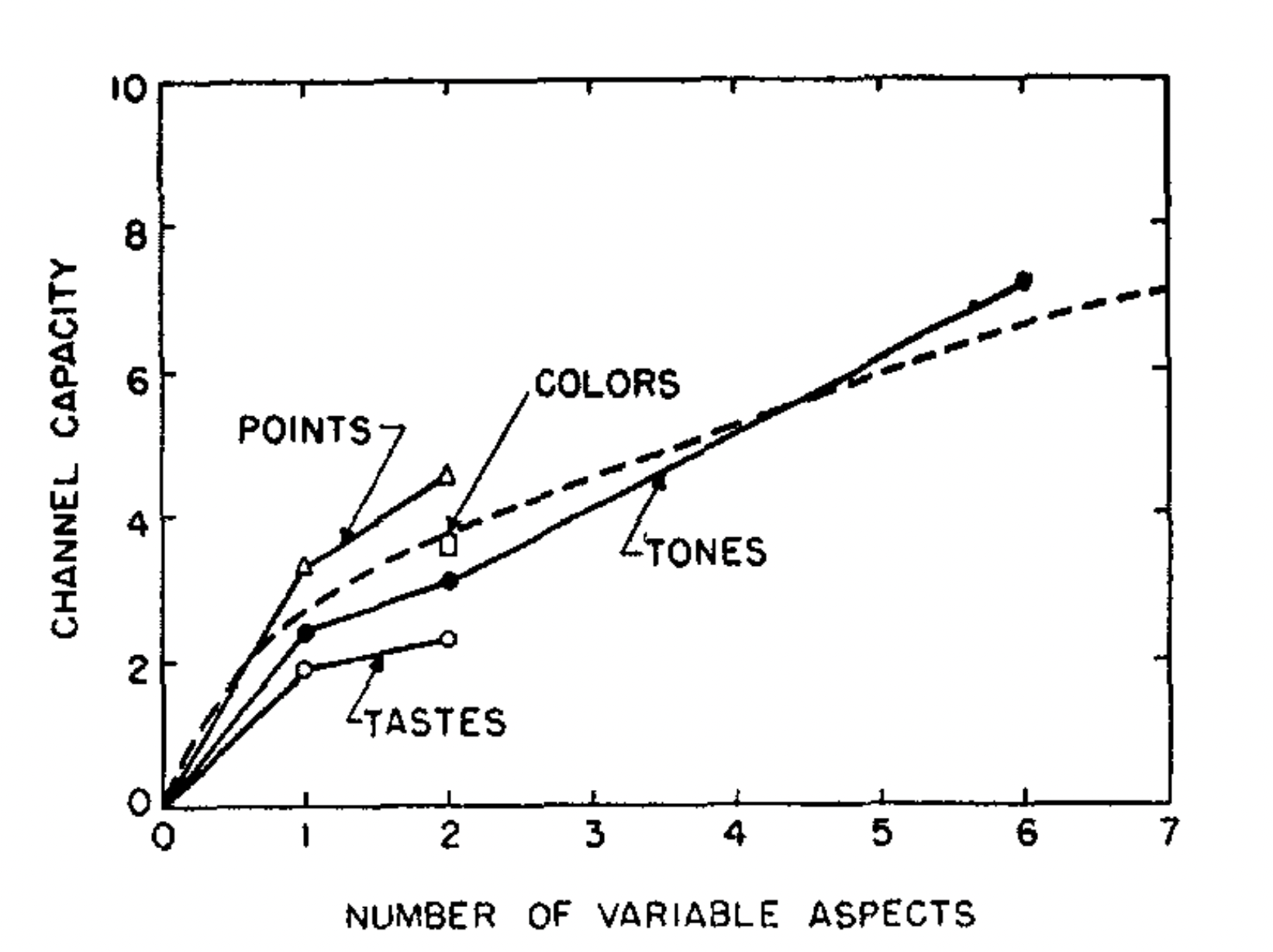
The point being that, as we add more variables to the problem, we increase the total capacity, but we decrease the accuracy for any particular variable. We can make relatively crude judgements of several things simultaneously. The above experiments and other exercises performed by linguists and phoneticians show that it is not that case that humans can only judge one element at a time, but rather than people are less accurate if they must judge multiple attributes simultaneously.
Subitizing
All this building once again towards the magical number seven, Miller refers to adjacent research involving identifying patterns of up to 200 dots on a screen.
On patterns containing up to five or six dots the subjects simply did not make errors. Below The performance on these small numbers of dots was so different from the performance with more dots that it was given a special name. Below seven, the subjects were said to subitize; above seven they were said to estimate.4
"Memory as the Handmaiden of Discrimination": different spans
Calling attention to the distinction between the subitization experiments and those which comprise the body of discussion in the rest of the paper, Miller expands on the "optimistic" notion of span of attention and categorizes the branch into a variety of spans:
The Span of Absolute Judgement
Which describes the results of the experiments thus far. For the unideimensional judgements, this span is "somewhere in the neighborhood of seven."5 This span can be extended by a variety of techniques which are worth bearing in mind when presenting information in any setting:
- Make relative, rather than absolute judgements
- Increase the number of dimensions along which stimuli can differ
- arranging the task in such a way that we make a sequence of several absolute judgements in a row, rather than simultaneously6
In this manner, we can extend the span of absolute judgement from seven to at least 150.
Span of Perceptional Dimensionality
Miller contends this is somewhere in the neighborhood of ten after which point the information gain from meta-comparison starts to taper off, but requires more empirical research
The Span of Immediate Memory
Which is measurable by forcing the test subject to retain multiple judgments at a time such that the process is no longer an experiment on absolute judgement, but on immediate memory. Miller underscores an important distinction between the two which causes the persecution: conflating the span of absolute judgement with immediate memory.
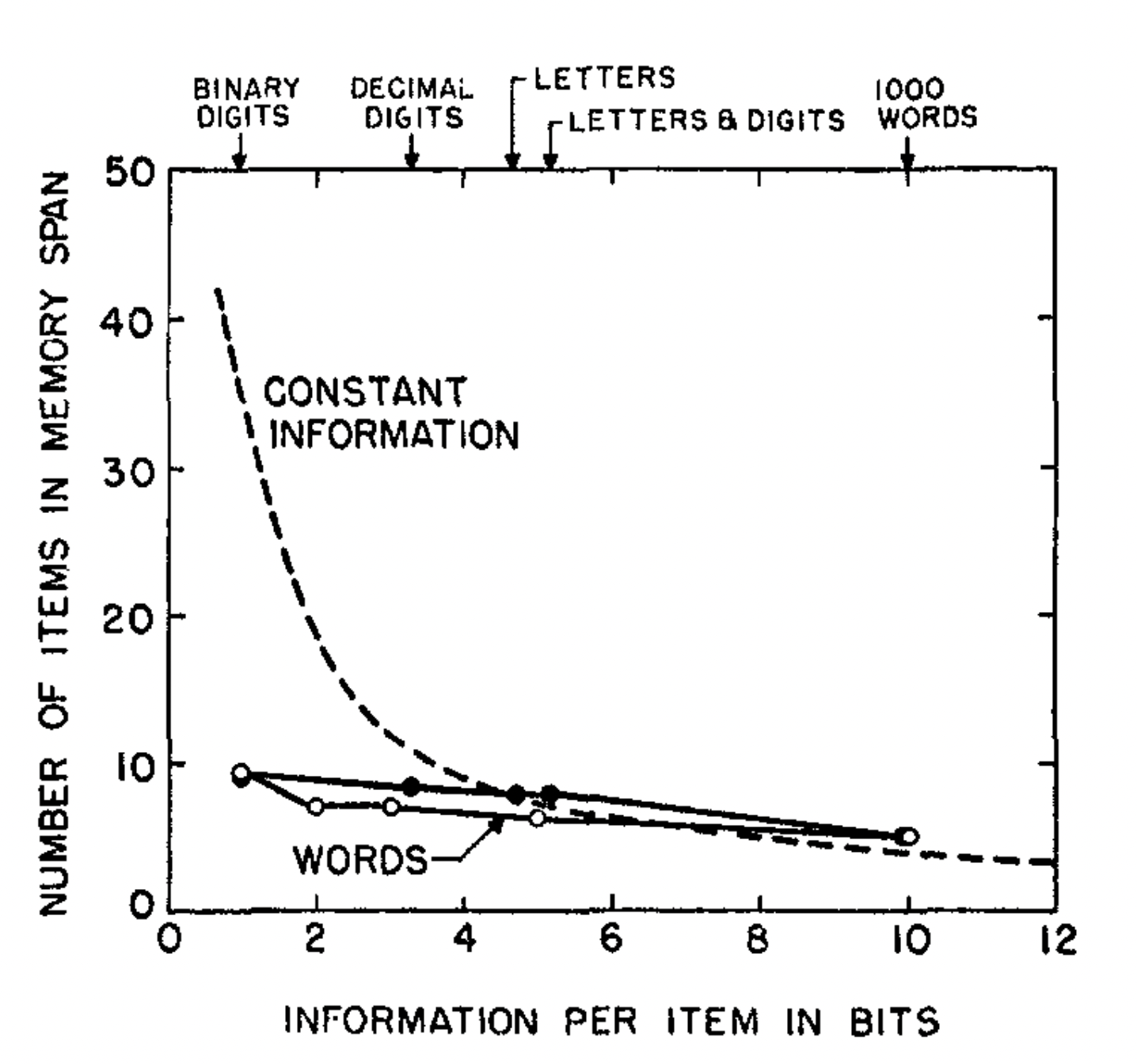
If they were the same or even as closely related as the data would suggest, a true commonality between the "spans" then invariant features in Absolute Judgement should also be invariant in the latter case. E.g. If the amount of information in the span of Immediate Memory is a constant, then the span should be short when the individual items contain a lot of information, and long when the items contain little information. This is not the case though!!

Perhaps the Best Party Trick
The key example used to demonstrate the persecution of the number seven is an exercise is memory recall of different element:
- Decimal digits which are worth about 3.3 bits apiece, for which we can recall about seven, for a total of 23 bits of information,
- Binary digits are worth 1 bit apiece, and so –if we buy into the mistaken conflation of absolute judgement and memory recall– we should be able to recall 23 of them,
- Isolated english words are worth about 10 bits a piece, and if the total amount of information is to remain invariant at 23 bits, then we should be able to only remember 2 or 3 words chosen at random.
Hayes tried this experiemnt on binary digits, decimal digits, letters, alphanumeric strings, and words and it was also replicated by Pollack with similar results which were clear in both: amount of information transmitted is not a constant, but increases almost linearly as the amount of information per item in the input is increased.
Despite the coincidence of the sinistral seven, the span of absolute judgement and immediate memory suffer quite different kinds of limitations. These experiments found that absolute judgement is limited by the amount of information, whereas immediate memory is limited by the number of items.
This distinction can be highlighted by considering the content of the experiments: bits vs. chunks. The number of bits of information is constant for absolute judgment and the number of chunks of information is constant for immediate memory, and the span of immediate memory seems to be almost independent of the number of bits per chunk
A chunk here has an ambiguous definition, due to the flexibility of the human brain to group things.
Recoding
A man just beginning to learn radio telegraphic code hears each dit and dah as a separate chunk. Soon he is able to organize these sounds into letters and the letters as chunks, then letters organize into words which become larger chunks, and eventually complete phrases form larger chunks and so on.
The point being that recoding is a learned skill! This process of recoding is analogous to the the way that a compiler works, taking chunks of dense, information rich language and translating it into an (mostly) un-chunked, low variance sequence of machine code.
for( i = 0; i < 10; i++ ) {
// loop body
}
li $t0, 10 # t0 is a constant 10
li $t1, 0 # t1 is our counter (i)
loop:
beq $t1, $t0, end # if t1 == 10 we are done
# loop body
addi $t1, $t1, 1 # add 1 to
t1 j
loop # jump back to the top
end:
(No self-respecting compiler would ever produce this assembly code, it's like -O0.2)
Similarly, with respect to the advantages of functional programming, the argument over imperative programming is that functional composition and statefulness makes it easier for us to mentally replicate the behavior of complex programs because we don't have to "waste" our seven ± 2 mental registers on errant moving pieces which might crop up something like in this (somewhat contrived) imperative snippet:
def aVeryComplicatedFunction(info: Info): List[Result] = {
var currIndex = 0 // probably going to go up
var results = list.empty[Result] // empty now, but we'll probably overwrite it later
var currentInfo = info // info currently, subject to change
var currRes: Result = null // current result is null, probably going to change
var loop = true // want to loop now, but it's a boolean, so that probably won't always be the case
while(loop && currIndex < info.length) {
// ... do something
}
}
Two years prior to Miller's paper, psychologist Sidney Smith conducted an experiment demonstrating that people have no issue parroting eight or so decimal digits, but only nine binary digits, despite the massive difference in information richness of each category of phoneme.
Sidney hypothesized that by recoding a string of binary digits as groups of decimals, subjects might be trained to recall strings of lengths more proportionate to their information density. E.g.
It is reasonably obvious that this kind of recoding increases the bits per chunk, and packages the binary sequence into a form that can be retained within the span of immediate memory.
And while such a recoding scheme did increase their span for binary digits across the board, the increase was once again not as large as expected for octal digits. Additionally, the few minutes used to teach participants the encoding/decoding scheme were likely insufficient. Smith argued that for the gap to be closed, the translation from one code to another must be almost automatic or the subject will fail to retain prior groups while struggling to encode the current.
With germanic patience he drilled himself on each recoding successively until he attained the result show below:

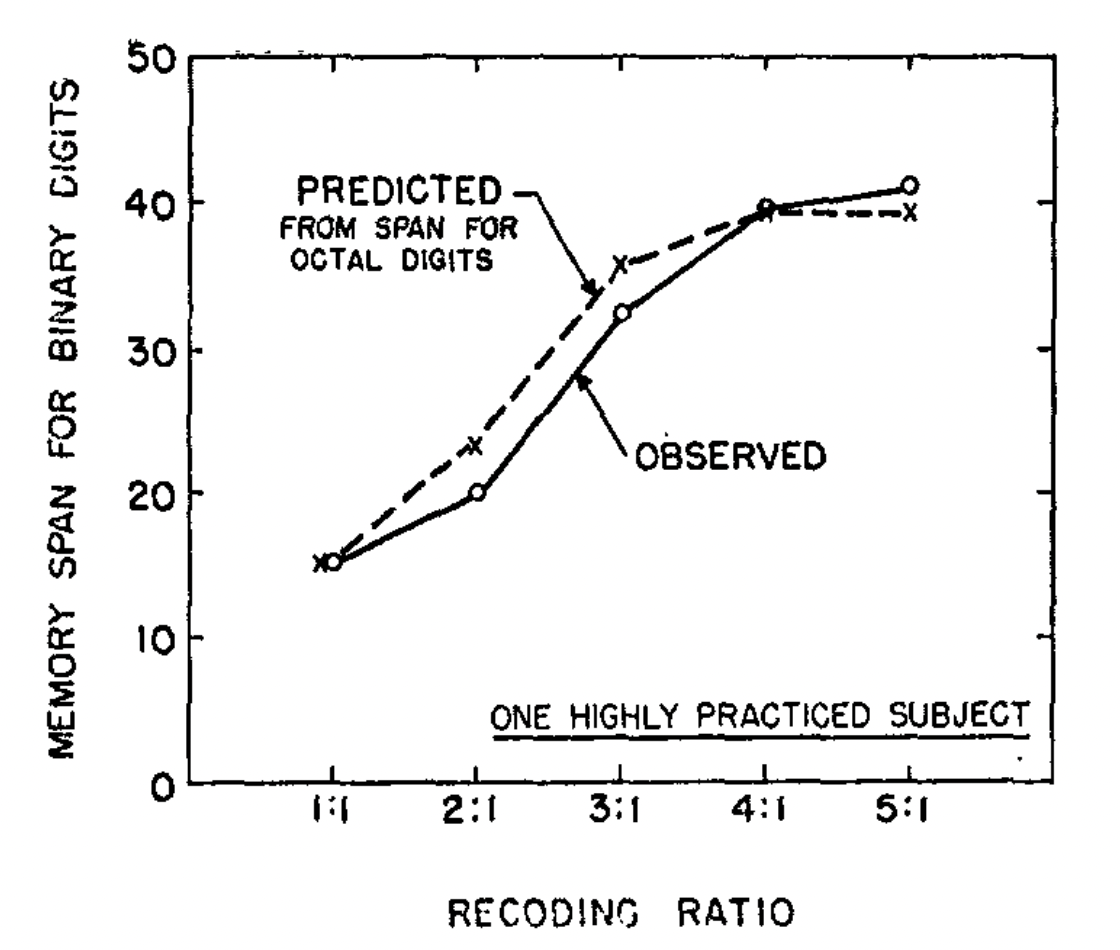
It is a little dramatic to watch a person get 40 binary digits in a row an then repeat them back without error.
which has got to be one of the most autistic party tricks I've ever imagined (and I say this with awe and envy, as someone who formerly prided themself in my ability to solve a Rubik's cube in various states of impairment, recite the alphabet backwards, name presidents or books of the bible by their index, etc.)
Miller points out that Recoding and Mnemonics are a regular part of daily life, and that "when we witness some event we want to remember, we make a verbal description of the event and then remember our verbalization" which is exactly what these Digest are!
The ultimate takeaway from this paper is as follows:
The span of absolute judgement and the span of immediate memory impose severe limitations on the amount of information that we are able to receive, process, and remember. By organizing the stimulus input simultaneously into several dimensions and successively into a sequence of chunks, we manage to break (or at least stretch) this informational bottleneck.
Conclusion
So, what's the meaning behind the magical number seven on my wrist? Miller suggests that it is only a pernicious, Pythagorean coincidence.
Footnotes and References
Footnotes
Cowan, Nelson. "George Miller's Magical Number of Immediate Memory in Retrospect: Observations on the Faltering Progression of Science." ↩
Nizami, Lance "Interpretation of Absolute Judgments Using Information Theory: Channel Capacity or Memory Capacity?" provides a survey of other psychological studies of Information Theory as well as more formal definitions of variance, covariance, etc. in terms of Information than the venn diagrams used by Miller ↩
They did the experiment in two ways, in one version they let the observer use any number on [1, 100] to describe the position of a point on a line, though they only presented stimuli on a fixed subset of those positions. In the other version, they limited the selectable positions to to only just those stimulus values that were possible. The two functions are so similar that it seems fair to conclude that the number of responses available to the observer had nothing to do with the channel capacity. That is– discrete vs. continuous domains of discrimination had little impact on transmittable information. ↩
He qualifies subitization in this particular experiment as a form of persecution because it does not closely align with the other experiments and instead appears to be a frustrating coincidence. ↩
This is some hardcore dude shit to say. The whole paper is a vibe. Compelling without being overbearing ↩