Strong Eventual Consistency
- Published on
- ∘ 52 min read ∘ ––– views
Previous Article
Next Article
An Introduction to the Album
Perhaps the most important part of a post-emo song is its totally incomprehensible song title. Not the arrangement, lyrics, unique tuning. No, it's the title which must be devoid of any relation to the contents or meaning of the song itself.
When viewed at a glance, any punk rock† tracklist worth its salt ought to be jarring, immersion-breaking, and puzzlingly disparate from message of the song, if any such meaning is even forthcoming. But, over time, eventually this pattern becomes an appreciable aesthetic touch, and strongly enough so that the zany titles become integral to the eidetic essence of an album or sequence of songs. To borrow the language of the papers discussed later on, the song titles are consistently offputting, with several bands appearing to pride themselves on incoherent discographies, which converge on a reliably pleasant listening experience.
† - I know at least a few readers will take offense with my liberal blending of genres, but they're welcome to respond with their own blog post.1
The analogy for the actual subject matter of discussion for this post kind of fizzles out here, but I'm going to lean into it regardless, trying (and failing) to draw connections between red-herring titles and conflict resolution in distributed systems.
I actually had no strong motivation to write about eventually consistent data types. I thought it would be a quirky playlist name, based on a phrase I vaguely remember reading several years ago in a paper about ¿key-value stores? or something like that. But I couldn't remember their significance, nor how they worked. So, naturally, I've spent the past couple weeks re-familiarizing myself with that paper, leapfrogging to contemporary developments, and naturally convincing myself that I understand conflict resolution as thoroughly as a hostage negotiator. This is the result of that rabbithole.
Scott Pilgrim v. My GPA
(The Byzantine Problem)
In distributed systems striving for eventual consistency (definition forthcoming), The Byzantine Problem is an analogy describing the need for a resolution protocol for imperfect information or component failure. Oftentimes, such protocols rely on consensus voting, proof of work, or prioritization of "leading" trustworthy nodes in the system.
A compromised component in a distributed system can stochastically exhibit symptoms of success and failure in completing whatever the distributed task is. A distributed task might be something along the lines of tallying views on a YouTube video,2 a simple fork-join task, or coordination of battle strategy against Ottoman combatants.
This presents the problem of isolating, or at the very least mitigating, the spread of compromised information to the rest of the system, and this introduces the measure of severity of such a breach to a system's integrity: Byzantine Fault Tolerance – the resilience of a system on the whole to such conditions.
In the titular metaphor, a group of generals must come to a consensus about whether to attack or to retreat. Each component of the distributed system (commonly referred to as a replica in the literature) may have its own strategic preference or signal (in this example, or - though signals need not be binary in general). To establish urgency in our hypothetical, we assume that a coordinated attack or retreat by all the generals (the system on the whole) is favorable to a fractured mobilization as the result of miscommunication, where each general acts according to their own strategy rather than that of the whole army.
To complicate the situation, some generals may be selectively treacherous (probabilistically, intentionally, etc. The Internet is a big place, and lots can go wrong), sending signal to some partition of their confederates, and signal to the others in an attempt to sew chaos on behalf of the Turks.
Additionally, as the army is physically separated (distributed) the integrity of their messages is at the whim of their messengers. Messengers can be bribed, intercepted, or be UDP packets: they might not correctly reflect the intent of the sender, nor even be received. Worse yet, they might not be consistent in their success or failures, making this a Byzantine problem.
Words That Rhyme with Different, Etc.
(Characteristics of Byzantine Problems)
- A Byzantine Fault occurs if any component in the system presents different symptoms to different observers.
- A Byzantine Failure occurs if a system on the whole is compromised due to Byzantine Faults in a system where consensus is required.
- A Byztantine Fault Tolerance is achieved if non-faulty components have a majority agreement on strategy (or whatever the subject of consensus is). "Majority," here, is also loosely defined. Some systems need only reach 51% consensus to function properly (such as a blockchain), others might require a 2/3 super majority (like a different blockchain), and some might need perfect accuracy (like sales of a precisely controlled commodity).
Formally: Given a system of components, where components are truthful, as well as a peer to peer communication channel, whenever component tries to broadcast a value , the other components are allowed to discuss with each other and verify the integrity of 's broadcast, the system will eventually settle on a common value .
Such a system is said to resist Byzantine Faults if broadcasts some value and:
- if is truthful, then all components agree on the value
- in any case, all truthful components agree on the same consensus value .
i just want to kickflip into the sunset and disappear
(Trivial Solutions to the Coordination Problems )
A default initial value or assumed vote can be given to all null or missing messages from unresponsive (or faulty!) components deemed untrustworthy or unreliable. Interpretation of the null value can be prearranged by the constituents of a system.
- Such a prearrangement fails for the Byzantine since, not only can reaching consensus be prevented by incomplete or faulty signals with otherwise perfect knowledge of the system, but reaching consensus may be prevented about whether or not a component is faulty in the first place.
Lvl. 2 Pidgey in a Masterball
(Solutions to Byzantine Problems)
The two primary solutions to Byzantine Problems I want to discuss here are Conflict-free Replicated Data Types (CRDTs)3 and more sophisticated conflict-resolving data structures called HashGraphs.
J-Kobb Schlepper (My Dog At My Paypal Account)
(Intro to CRDTs)
CRDTs were developed in response to the existential problem posed by the need for eventual consistency that cannot be ameliorated by angsty music alone. Instead we have this "simple, theoretically sound approach," covered at length in the original 2011 paper by Shapiro et al: "A comprehensive study of Convergent and Commutative Replicated Data Types."4 CRDTs in general aim to do away with the need for reaching consensus. In doing so, they indirectly address the Byzantine Problem by defining a protocol for offline, stateful consensus.
In the offline scenarios specifically, if attempts are made to talk off-machine, we want to enqueue outbound messages and give responses deadlines rather than throwing an exception wherever possible. In the case where we cannot adhere to this rule, we need to gracefully handle the offline scenario. E.g., when talking to a centralized authorization service, a user may be locked out if we (acting as the Auth Service) can't verify their security access permissions due to a network outage. Once we are again able to verify their requisite permissions, and a validity window for the answer, we should cache the response to prevent a lapse in availability for them in the future.

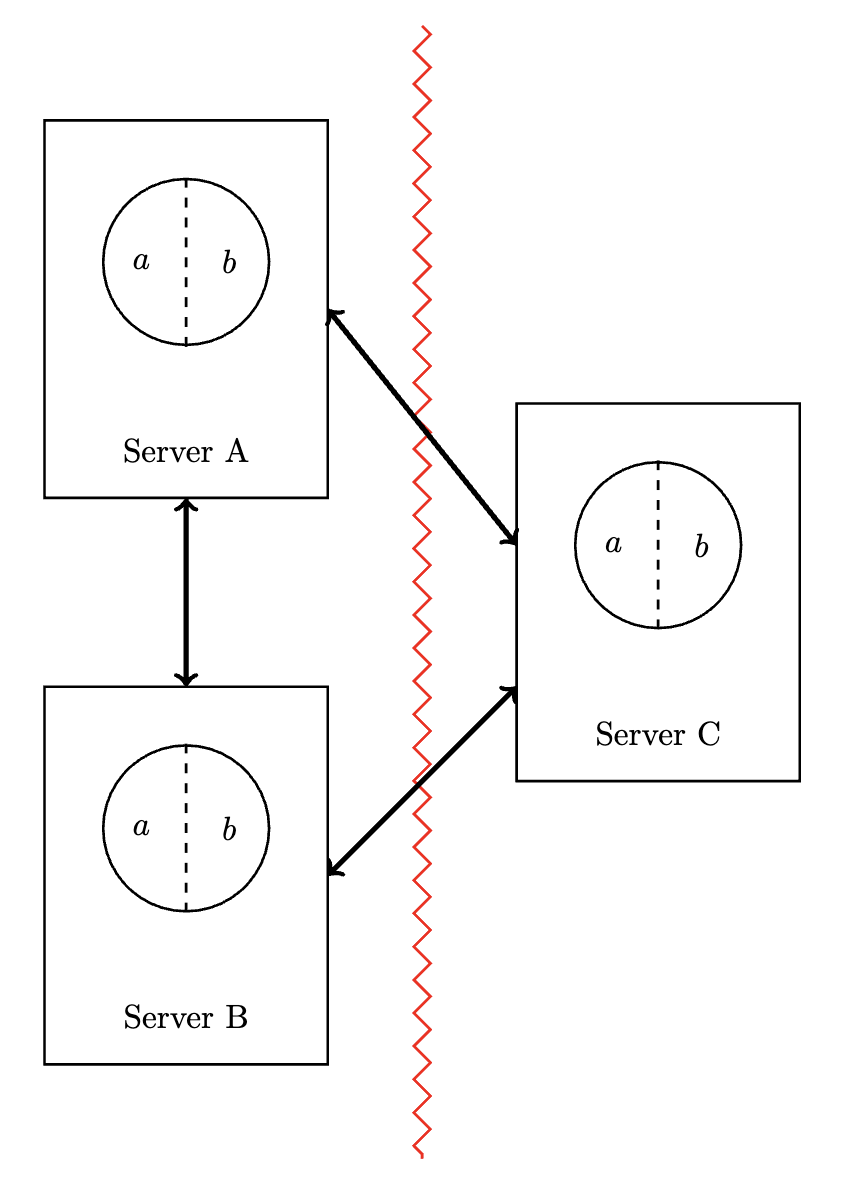
It is not possible to come to consensus with a system that cannot be communicated with. Even under a resolution protocol which uses default null values for missing votes as would be the case for outbound messages in the above offline example, only one side of the partition can be in the majority (Servers A and B), and the minority does not want to lose its state outright.
It is fruitless to strive for agreement in such scenarios, but a consistent view of the past with distributed conflict resolution is achievable.
A protocol like Paxos for achieving consensus involves seeking a majority vote of a leader, and voting on the next move that the state machine is to take. On the event of a hopefully-exceptional network partition, updates propagating across the network need to terminate in the minority partition (Server C), lest the state be lost when the partition (hopefully) heals.
There are numerous drawbacks to this framework, the most obvious being the assumption that partitions are infrequent and/or brief.
dragon ball z budokai tenkaichi 4
(Types of CRDTs)
According to the seminal paper, for replicas to return the same result for all query operations after such a partition is introduced, two conditions must be met:
- safety: If the causal history of replicas and is the same, the abstract state of these replicas must be equivalent
- liveness: If some element is in the causal history of , then it will eventually be in the causal history of
Inductively, the pairwise eventual consistency defined by these two properties guarantees convergence for any non-empty subset of replicas contingent on the eventual receipt of all updates.
Fuck, Dantooine Is Big
(Example of a CRDT)
Suppose we have several servers spread across the world – in warzones, hotbeds of natural disaster, and other areas prone to network outages like my mom's basement whenever I hop on the sticks in Warzone: say Aleppo, Abescon, and Alexandria.
We have the simple task of utmost importance: track the highest value observed by any of the severs (my killstreak 😤 😤) across our shared database. Our goal is to provide a protocol with properties of commutativity, associativity, and idempotency. (this all sounds awfully functional to me).
In this trivial example, a merge function like satisfies our needs. Within each replica, if , we can ignore, dismiss, discard value in favor of . After each update, a replica will broadcast to all its peers indicating that a new maximum value has been observed (loadout drop is inbound). These updates will converge on the system's known maximum value. This is similar to the common leader election algorithm, except in this case, the updates are continuous, whereas an election has a discrete end once all votes are caster and tallied, whereas this system can always observe a new, higher value.
Each server keeps track of the highest observed value for itself as well as for all other replicas, and updates those counters indexed by replica. For example, Server A's internal count might be:
{
"A": 11,
"B": 20
}
and Server B, having received one final update from Server C before my dominance got the home router taken offline:
{
"A": 4,
"B": 28,
"C": 8
}
When A and B next communicate with one another, each will attempt to merge their respective states by taking the maximum value observed for the same key by two replicas:
merge({ "A": 11, "B": 20}, { "A": 4, "B": 28, "C": 8})
= {
"A": 11,
"B": 28,
"C": 8
}
(Joe Gets Kicked Out of School for Using) Drugs With Friends (But Says This Isn't a Problem)
(More Formal Defintions)
There are two main categories of CRDTs:
- commutative - which rely on replicated operations – designed to commute
- convergence - which rely on replicating state, executing operations on a primary component
In both cases, the higher order goal is to avoid the need for coordination by ensuring that actions taken independently can't conflict with each other and thusly can be composed at later point in time [eventually].
Visited Salmon, I Mean Transit Balcony
(State-Based CRDTs)
State-Based CRDTs maintain replicated state across a distributed system via composable Least Upper Bound functions which must be defined over their constituent data. In the prior example, the function is a literal LUB, but our data will usually have a more complex structure than singular numbers.
Formally, our set of data values together within a LUB-based partial order function forms a join semilattice5 where the "join" is a property of the LUB which governs how the lattices may be merged. If values only ever increase, the lattice is monotonic, and said to be a CRDT. A LUB can be thought of as the closest common ancestor of two elements in a hierarchical collection of some sort.
Vanilla-Scented Laser Beams
(Operation-Based CRDTs)
This variety of object assumes a channel which maintains a linear ordering of message delivery to communicate between replicas. Operations outside of this delivery order are called "concurrent," and if they are commutative, than all operations consistent with the order of the deliver channel are equivalent, so the distributed state will be convergent across all replicas.
Hey Ken, Someone Methodically Mushed the Donuts
(Nuff Bout CRDTs – this would be an interlude)
CRDTs avoid the need for consensus by instead relying on definitions for behavior in light of conflicting observations.
It's feasible to due away with git merge conflicts entirely if the version control system is treated as a CRDT with some rule which enforces a Least Upper Bound on the commit history. For example, simply take the most recent provided timestamp of each conflicting event to be the "maximum." This obviously doesn't work in practice, but it's possible.
Umbrellas and Beersocks
(The FLP Theorem)
Before diving into the advancements offered by HashGraphs, it's first worthwhile to survey problems of distributed consensus and pickup some useful terminology. The most relevant to the discussion about HashGraphs which do rely on consensus (sort of) being the eponymous Fischer-Lynch-Paterson Theorem introduced in "Impossibility of Distributed Consensus with One Faulty Process."6
The problem the authors present is that getting reliable, asynchronous processes –amidst some faulty ones– to agree on even just one binary value is very hard. They note that every protocol in this asynchronous case can be a victim of possible nontermination with even just one faulty process.
The example problem instance they use is referred to as the "transaction commit problem" for a distributed database which is roughly similar to the aforementioned git merge conflict problem: all the database managers that have participated in processing a transaction must agree on whether or not to accept the transaction's results on the database.
Whatever decision is made must be executed by all managers in order to maintain consistency across the replicas i.e. consensus must be reached. If all of the managers are reliable, then the solution is trivial. However, even non-Byzantine faults such as crashes, network partitions or outright failures, lost, distorted, and/or duplicate messages present problems for the trivial (arguably naive) scenario where replicas trust one another.
The titular crux of the paper is that no completely asynchronous protocol can tolerate even a single unannounced process death. This constraint is so overbearing that the authors don't even grapple with the Byzantine complications, and further assume reliable message channels. They make these nifty assumptions to show the fragility of distributed systems in general, conversely making their main theorem as widely applicable and robust as possible.
The asynchronicity of the systems being considered is also integral to their asserted fragility. No assumptions are made about relative speeds of processes, or delays in their receipt. Processes don't have access to a universal, synchronized clock, so timeout-based algorithms are not applicable. Therefore, process death is indistinguishable from a slow process or high network latency.
Thrashville 1/3
(Model)
Processes are state machines with potentially infinitely many states which communicate via messages sent between each other. In one discrete time step, a process may attempt to:
- Attempt to receive a message by performing a local computation as to whether an message was delivered to it
- Send arbitrarily finite amounts of messages to other processes
If any truthy processes receive the message, then via an assumed atomic broadcast capability (from the generous assumption of a reliable communication channel), all truthy processes eventually will too. In other words, every message is eventually delivered as long as the other processes make sufficiently infinite attempts to receive it.
There's some lore on the matter:
The asynchronous commit protocols in current use all seem to have a “window of vulnerability”- an interval of time during the execution of the algorithm in which the delay or inaccessibility of a single process can cause the entire algorithm to wait indefinitely. It follows from our impossibility result that every commit protocol has such a “window,” confirming a widely believed tenet in the folklore.
A Consensus Protocol is an asynchronous system of processes.
- Each process has an input register , an output register , and an unbounded amount of internal storage.
- Values in the input and output registers, together with the program counter and internal storage, comprise the internal state of a process.
- Initial States prescribe fixed starting values for all but the input register. The output register is initially set to .
- Decision States are those in which the output register has a value of 0 or 1.
- acts deterministically according to a transition function which cannot change the value of the output register; is "write-once."
- Messages between processes are tuples of the form where
- is the target processes
- is the message value in some alphabet
- The Buffer is a multiset of messages that have been dispatched but not yet received, and supports two operations:
- : places in the message buffer
- : may delete some message from the buffer if it exists and returns , in which case we say that the message was delivered, otherwise it returns a special null marker indicating that the buffer was unchanged (and the process, message combination was not found)
The buffer can act non-deterministically (at the hands of non-truthy processes, perhaps), subject only to the condition that if is performed infinitely-many times, then the buffer is eventually emptied: all messages are delivered.
A Configuration of the system is comprised of the internal state of each process, together with the contents of the message buffer.
- An Initial Configuration is one in which each process starts at an initial state and the message buffer is empty.
- A Step takes one configuration to another via primitive step by a single process and occurs in two phases:
- First, is performed on the message buffer in to obtain
- Second, depending on 's internal state , as well as , the process enters a new internal state and sends a finite set of messages to other processes.
Since processes are deterministic, the step is completely described by the event which can be thought of as receipt of by . We say denotes the resulting config, or that can be applied to .
- can always be applied to , so it is always passible to take another step. This event is the identity on . (are your categorical senses tingling yet?)
A Schedule from is a possibly infinite sequence of events that can be applied in order, starting from . The associated sequence of steps is called a run. If is finite, is the resulting configuration, said to be reachable from . We only need consider configurations accessible from some initial configuration.
- Lemma: Suppose that from some configuration , the schedules lead to respectively. If the sets of processes taking steps in these schedules are disjoint, then and lead to the same configuration

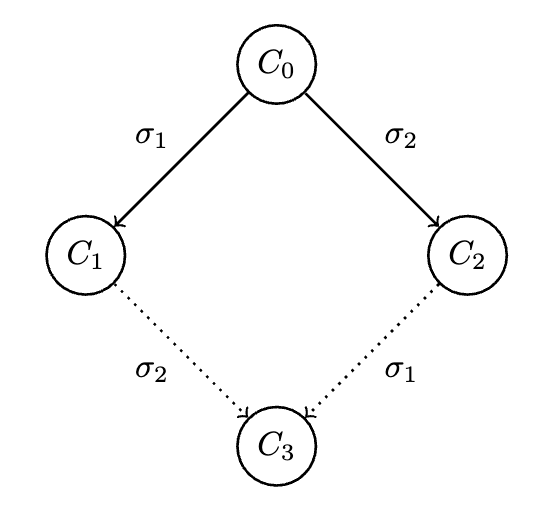
A configuration has decision value if some process is in a decision state such that .
A consensus protocol is said to be partially correct iff
- No accessible configuration has more than one decision value
- For each ,7 some accessible configuration has decision value
A process is non-faulty ("truthy") in a run provided that it takes infinitely many steps, and is faulty 🎩 otherwise. A run is admissible provided that at most one process is faulty and all messages to the other truthy processes eventually received.
The main theorem of the paper shows that every partially correct protocol for the consensus problem has some admissible run that is not a deciding run. Therefore, no consensus protocol it totally correct in spite of one fault.
The rest of the the paper includes supporting lemmas and further stipulations about conditions of failure, which are all fascinating in their own right, but need not be replicated here.
A natural and important problem of fault-tolerant cooperative computing cannot be solved in a totally asynchronous model of computation. These results do not show that such problems cannot be “solved” in practice; rather, they point up the need for more refined models of distributed computing that better reflect realistic assumptions about processor and communication timings, and for less stringent requirements on the solution to such problems
frankie thinks she's punk rock but she's just a POSER!!! (demo)
(Swirlds HashGraph – AKA Solving the Problem in Practice)
With the FLP Theorem in our back pocket, we are ready to confront the HashGraph approach to achieving fair, fast and Byzantine-Fault-tolerant conensus developed by Swirlds. The distributed S/PaaS company published their white paper including proofs of the fault-tolerance of their HashGraph approach in 2016,8 and hot dayum it seems pretty cool.
The abstract claims that their proposal for a new kind of replicated state machine
achieves fairness, in the sense that it is difficult for an attacker to manipulate which of two transactions will be chosen to be first in the consensus order. It has complete asynchrony, no leaders, no round robin, no proof-of work, eventual consensus with probability one, and high speed in the absence of faults. It is based on a gossip protocol, in which the participants don’t just gossip about transactions. They gossip about gossip. They jointly build a hashgraph reflecting all of the gossip events. This allows Byzantine agreement to be achieved through virtual voting. Alice does not send Bob a vote over the Internet. Instead, Bob calculates what vote Alice would have sent, based on his knowledge of what Alice knows. This yields fair Byzantine agreement on a total order for all transactions, with very little communication overhead beyond the transactions themselves.
Whereas the authors of the FLP theorem offered generous assumptions about the friendliness of the system at play, Swirlds assumes the opposite: that the system and its external conditions be as hostile as possible. The rhetorical purpose being the same – to prove the most robust form of applicability and/or correctness as possible. They use a strong definition of "Byzantine" to mean that just under of all components within the system can be adversaries colluding with one another, deleting or corrupting or delaying messages, who also can have full control of the network (and thus, the communication channel) with the same caveat offered by the FLP theorem, that if a truthy component infinitely attempts to send a message to another component, it must be received eventually.
The system is totally asynchronous. It is assumed that for any honest members Alice and Bob, Alice will eventually try to sync with Bob, and if Alice repeatedly tries to send Bob a message, she will eventually succeed. No other assumptions are made about network reliability or network speed or timeout periods. Specifically, the attacker is allowed to completely control the network, deleting and delaying messages arbitrarily, subject to the constraint that a message between honest members that is sent repeatedly must eventually have a copy of it get through.
In spite of the FLP theorem above, the authors assert that their completely asynchronous, nondeterministic HashGraph achieves consensus with a probability of 1.
They acknowledge other consensus algorithms like proof of work blockchains, and leader-based voting, as well as other Byzantine protocols which attempt to address the pitfalls of the former two, and point out that even the lattermost approaches require up to message exchanges to achieve consensus.
HashGraph sends no votes at all over the network, because all voting is virtual.
Welcome to Castle Irwell
(Core Mechanisms)
It's worth noting that a HashGraph is a Graph of Hashes, and not the other way round: something akin to a HashMap of Graphs, though that's also fun to think about. They outline the core mechanisms of the HashGraph as follows.
Eventualities
(Events)
Generally, transactions under dispute are called events. An event is defined to be an ancestor of event if is , or a parent of , or a parent of a parent of and so on. It is also a self-ancestor of if is , or a self-parent of , or a self-parent of a self-parent of and so on.
The round of an event is defined to be , where is the maximum round number of the parents of (or if it has no parents), and is defined to be if can strongly see more than witnesses in round (or if it can’t).
- Lemma: If hashgraphs and are consistent, and decides a Byzantine agreement election with result in round and has not decided prior to , then will decide in round or before.
- This lemma provides a bound on the eventuality of strong consistency, though implicit assumptions of network partitions or lackthereof need still be considered.
Had 2 Try
(Example of Round Delineation)

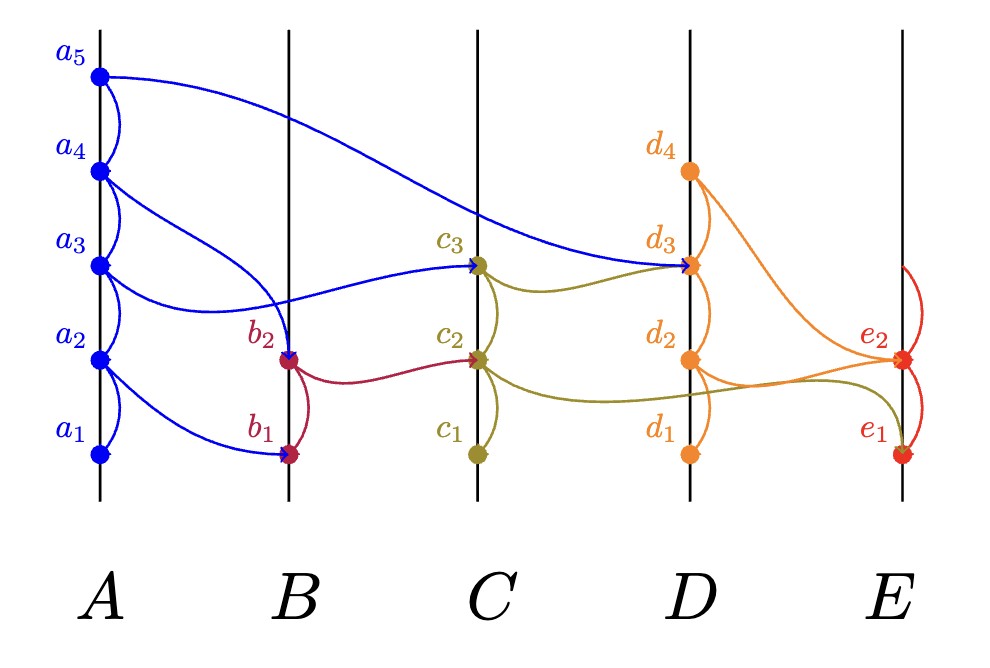
Here, all events except for are in the initial round (round 1). Those 3 nodes are able to strong see a supermajority of all nodes in round (), therefore they all sign themselves as being members of round 2, and all of their parent nodes will also have at least round 2 status.
The round received number of an event is defined to be the first round where all unique famous witnesses are descendants of . If any event strongly sees a supermajority of events from the current or previous round , it advances its round counter to .
A pair of events is a fork if and have the same creator, but neither is a self-ancestor of the other.
- Lemma: If the pair of events is a fork, and is strongly seen by event in hashgraph , then will not be strongly seen by any event in any hashgraph that is consistent with .
An honest ("truthy") member tries to sync infinitely often with every other member, creates a valid event after each sync (with hashes of the latest self-parent and other-parent), and never creates two events that are forks with each other.
Any member can created a signed transaction at any time. All members get a copy of it (eventually), and the system converges on Byzantine agreement of the linear ordering of those transactions.
It is not enough to ensure that every member knows every event. It is also necessary to agree on a linear ordering of the events, and thus of the transactions recorded inside the events.
Which is particularly challenging in the asynchronous setting, as illustrated by the FLP theorem: every such exchange or reliance on an ACK introduces an opportunity for unavoidable failure.
Our Love Is Dog
(Fork Cheating Example)
Suppose Bob creates an event with a certain self-parent hash pointing to his previous event . Then Bob creates a new event , but gives it a self-parent hash of , instead of giving it a self-parent hash of as he should. This means that the events by Bob in the hashgraph will no longer be a chain, as they should be. They will now be a tree, because he has created a fork. If Bob gossips to Alice and to Carol, then for a while, Alice and Carol may not be aware of the fork. And Alice may calculate a virtual vote for that is different from Carol’s virtual vote for . So it is possible for a fork to be spread across consistent hashgraphs. In this case, there may be a moment when Alice has a hashgraph containing but not , and Carol has a hashgraph with and not , and so a fork exists, but neither member is yet aware of the fact that it is a fork.

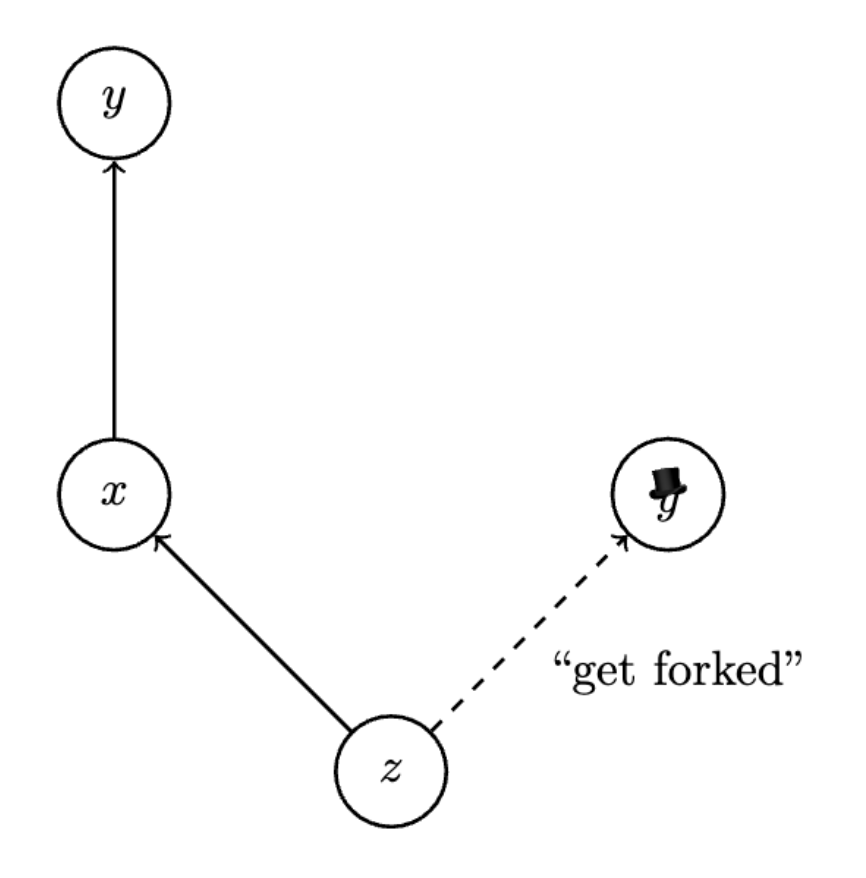
The hashgraph consensus algorithm prevents this attack by using the concept of one state seeing another, and the concept of one state strongly seeing another. These are based on definitions of ancestor and self-ancestor such that every event is considered to be both an ancestor and self-ancestor of itself.
shlonkey kong
(HashGraph)
The HashGraph is data structure that records who gossiped to whom, and in what order. Every member has a copy of the hashgraph. If Alice and Bob both have the same hashgraph, then they can calculate a total order on the events according to any deterministic function of that hashgraph, and they will both get the same answer. Therefore, consensus is achieved, even without sending vote messages.
Whereas git maintains a graph of cryptographic hashes representing versions in a tree, where edges are the diffs between them, it stores no record of how the components communicated. The HashGraph primarily records the history of how its components communicated. "Alice send Bob all the events that she knows that he doesn't"
Suppose Alice has hashgraph and Bob has hashgraph . These hashgraphs may be slightly different at any given moment, but they will always be consistent. Consistent means that if and both contain event , then they will both contain exactly the same set of ancestors for , and will both contain exactly the same set of edges between those ancestors. If Alice knows of and Bob does not, and both of them are honest and actively participating, then we would expect Bob to learn of fairly quickly, through the gossip protocol. The consensus algorithm assumes that will happen eventually, but does not make any assumptions about how fast it will happen. The protocol is completely asynchronous, and does not make assumptions about timeout periods, or the speed of gossip, or the rate at which progress is made.
- Hashgraphs and are consistent iff for any event contained in both hashgraphs, both contain the same set of ancestors for , with the same parent and self-parent edges between those ancestors.
- Lemma: All members have consistent HashGraphs.
if ur leffen then im chillindude
(Gossip about Gossip)
The HashGraph is spread through the gossip protocol. the information being gossiped about is the history of the gossip itself. This uses very little bandwidth overhead beyond simply gossiping the events alone.
- A member such as Alice will choose another member at random, such as Bob, and then Alice will tell Bob all of the information she knows so far. Alice then repeats with a different random member. Bob repeatedly does the same, and all other members do the same. In this way, if a single member becomes aware of new information, it will spread exponentially fast through the community until every member is aware of it.
Gossiping a hashgraph gives the participants a great deal of information. If a new transaction is placed in the payload of an event, it will quickly spread to all members, until every member knows it. Alice will learn of the transaction. And she will know exactly when Bob learned of the transaction. And she will know exactly when Carol learned of the fact that Bob had learned of that transaction. Deep chains of such reasoning become possible when all members have a copy of the hashgraph. As the hashgraph grows upward, the different members may have slightly different subsets of the new events near the top, but they will quickly converge to having exactly the same events lower down in the hashgraph. Furthermore, if Alice and Bob happen to both have a given event, then they are guaranteed to also both have all its ancestors. And they will agree on all the edges in the subgraph of those ancestors. All of this allows powerful algorithms to run locally, including for Byzantine fault tolerance.
Gossip about gossip requires little overhead communication (compared to gossip about the transactions themselves) as components comunicate only the diffs of their signatures of observing new transactions. Even these signatures can be compressed: "With appropriate compression, this can be sent in very few bytes, adding only a few percent to the size of the message being sent."
Meet Me in Montauk
(Virtual Voting)
Every member has a/is a copy of the HashGraph, so Alice can compute what Bob would have sent her, if they had been adhering to a traditional Byzantine consensus protocol which required vote-sending. Every member can reach agreement on any number of decisions, without a single vote ever being sent. The HashGraph alone is sufficient. So zero bandwidth is used, beyond simply gossiping the HashGraph.
Virtual voting has several benefits. In addition to saving bandwidth, it ensures that members always calculate their votes according to the rules. If Alice is honest, she will calculate virtual votes for the virtual Bob that are honest. Even if the real Bob is a cheater, he cannot attack Alice by making the virtual Bob vote incorrectly
- Lemma: For any single YES/NO question, consensus is achieved eventually with probability
Voting on the acceptance of a proposed event occurs as follows:
- An event in round computes whether it is able to see the prior transaction
- computes whether it is able to strongly see the
- computes whether it is able to strongly see a supermajority of events
- If so, it advance to a new round, and checks if a supermajority of nodes in can strongly see a witness of
- If so, the witness of is considered famous, and is committed
The "virtual" part occurs during (3) and (4) by computing the visibility vectors of other nodes locally.
If any event strongly sees a supermajority of events from the current or previous round , it advances its round counter to .
Art School Wannabe
(Famous Witnesses)
A witness is the first event created by a member in a round
The community could put a list of transactions into order by running separate Byzantine agreement protocols on different yes/no questions of the form “did event come before event ?” A much faster approach is to pick just a few events (vertices in the hashgraph), to be called witnesses, and define a witness to be famous if the hashgraph shows that most members received it fairly soon after it was created. Then it’s sufficient to run the Byzantine agreement protocol only for witnesses, deciding for each witness the single question “is this witness famous?” Once Byzantine agreement is reached on the exact set of famous witnesses, it is easy to derive from the hashgraph a fair total order for all events.
Shred Cruz?
(Seeing and Strongly Seeing)
- An event can see event if is an ancestor of , and the ancestors of do not include a fork by the creator of

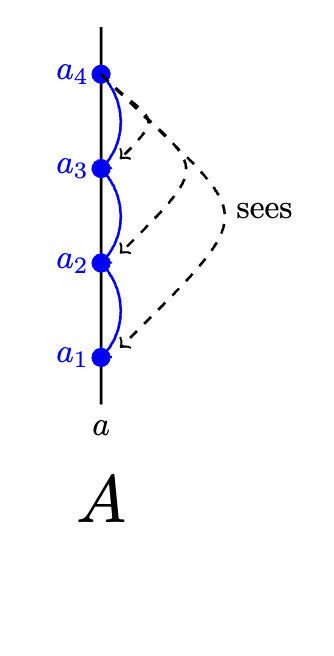
Imagine if I had the patience to make an interactive graph for this. It would be so sparkly. Instead you must use your imagination.

can see by way of e.g.
can see by way of e.g.
can see by way of e.g.
Etc.
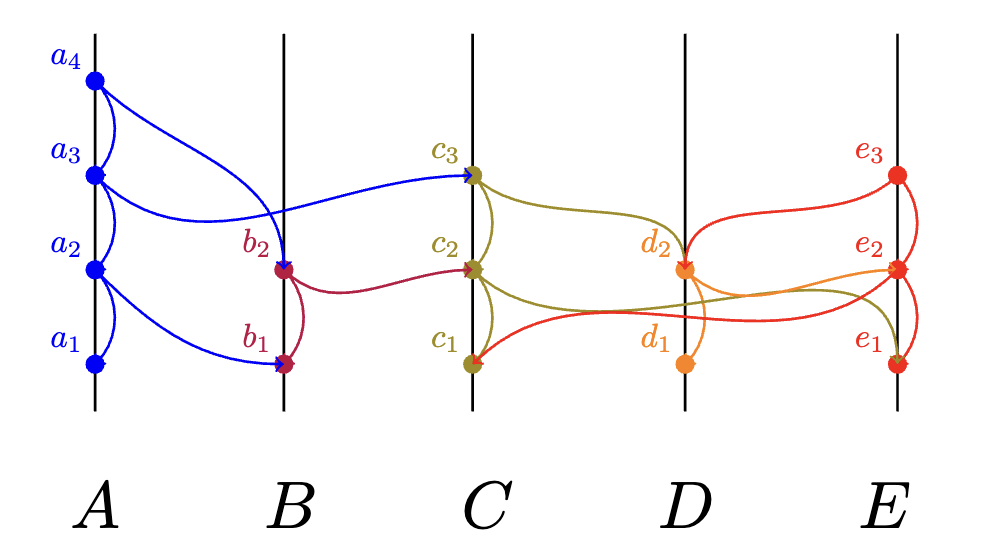
- An event can strongly see event if can see and there is a set of events by more than of the members such that can see every event in , and every event in can see
Given any two vertices and in the HashGraph, it can be immediately calculated9 whether can strongly see , which is defined to be true if they are connected by multiple directed paths passing through enough members. This concept allows the key lemma to be proved: that if Alice and Bob are both able to calculate Carol’s virtual vote on a given question, then Alice and Bob get the same answer. That lemma forms the foundation for the rest of the mathematical proof of Byzantine agreement with probability one.
If there are members, a witness event can strongly see an event , if can see more than events by different members, each of which can see .
Consider the following state snapshot of a HashGraph:

has three paths that strongly see (grouped by which witnesses they pass through):
():
():
():
While none of the paths individually traverse a super majority of nodes, together they collectively go through four nodes B, C, D, and E, thus strongly sees .
Zepplin V (The House That Ewald Built)
(Fairness)
The authors stipulate that it should be difficult for a small group of attackers to unfairly influence the order of transactions chosen as the consensus, and that the order of transactions needs to be preserved.
For some applications, the exact order does not matter, but for a stock market it can be critically important that this decision be made fairly.10
As noted, an inherent flaw with the leader-reliant algorithms such as those of Paxos or Raft is that –regardless of the means used to select a hopefully-truthy leader– that component becomes a single point of failure, and therefore an easy target.11
In any case, the leader could arbitrarily decide to ignore Alice or Bob's reported transactions for a period of time, delaying one of them, to force one transaction to come after another. If the goal is distributed trust, then no single individual can be trusted
Additionally, given the nature of consensus needing to be reached by at least witnesses in a round, the structure of the HashGraph acts as a deterrent to attacks predicated on slowing the network. Failures resulting from (real) "total control" over the network are not considered as flaws of the protocol:
The Byzantine proofs assume the attackers control the internet, and can delay arbitrary messages. If attackers actually had that power, they could simply disconnect Alice from the internet for as long as it takes for Bob to send a transaction and have it recorded. This could be done on the real internet by launching a denial of service attack, flooding every computer with packets from Bob in an attempt to prevent Alice from communicating. Of course, this would also be effective if Alice were communicating with a central server, so it could be considered more a failure of the internet than a failure of the consensus system.


(Amateur Cartography)
Fastness (A HashGraph has 99 pace)
Throughout the paper, the authors provide ample discussion for means of compression or further reducing the overhead of the HashGraph without ever compromising the correctness of the structure on the whole.
The concern for overhead is almost humorously gratuitous. The priority for performative resolution of Byzantine problems is highlighted by the discussion of packing witnesses and visibility vectors into a single integer for optimal ALU consumption.

Naruto Themed Sexting
(Example of How it Works)
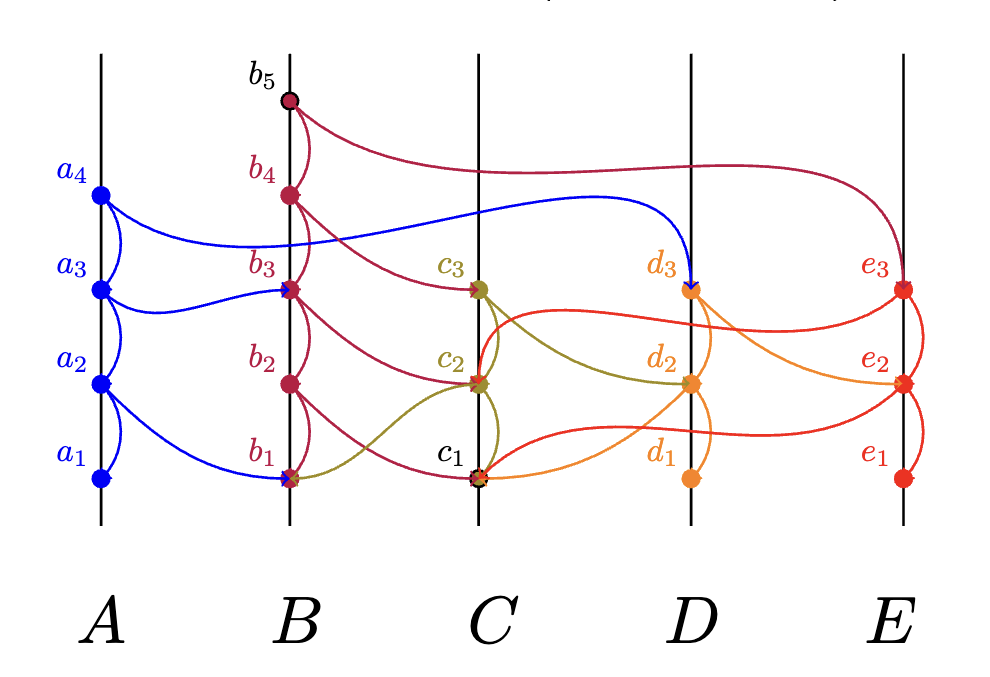
First, we start with the initial states for a HashGraph with four members. Each node has it's own root event:

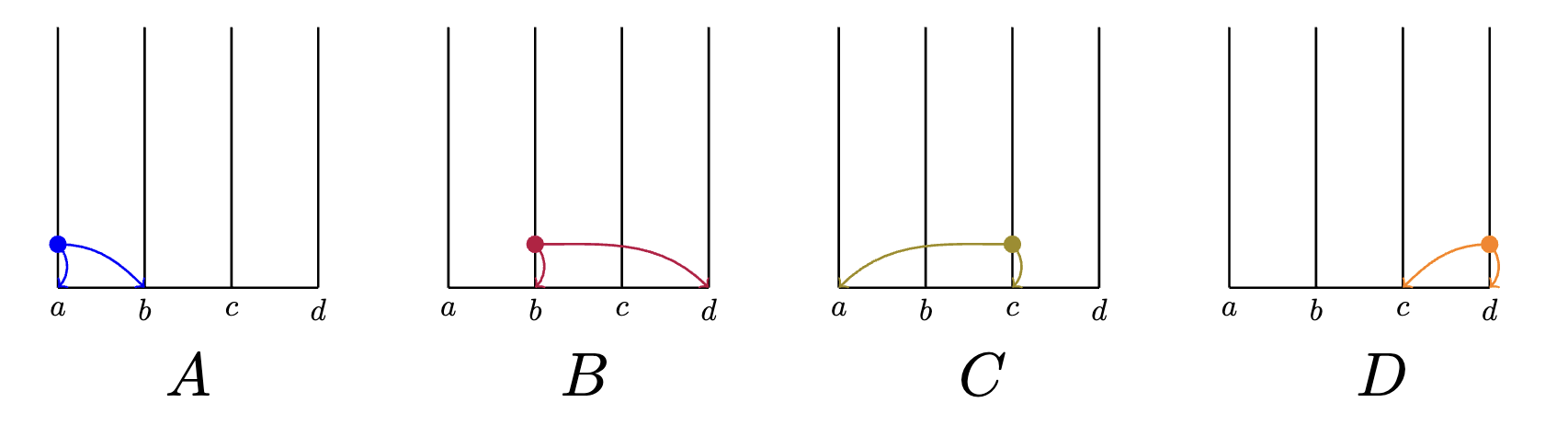
Suppose receives an event from and updates itself:

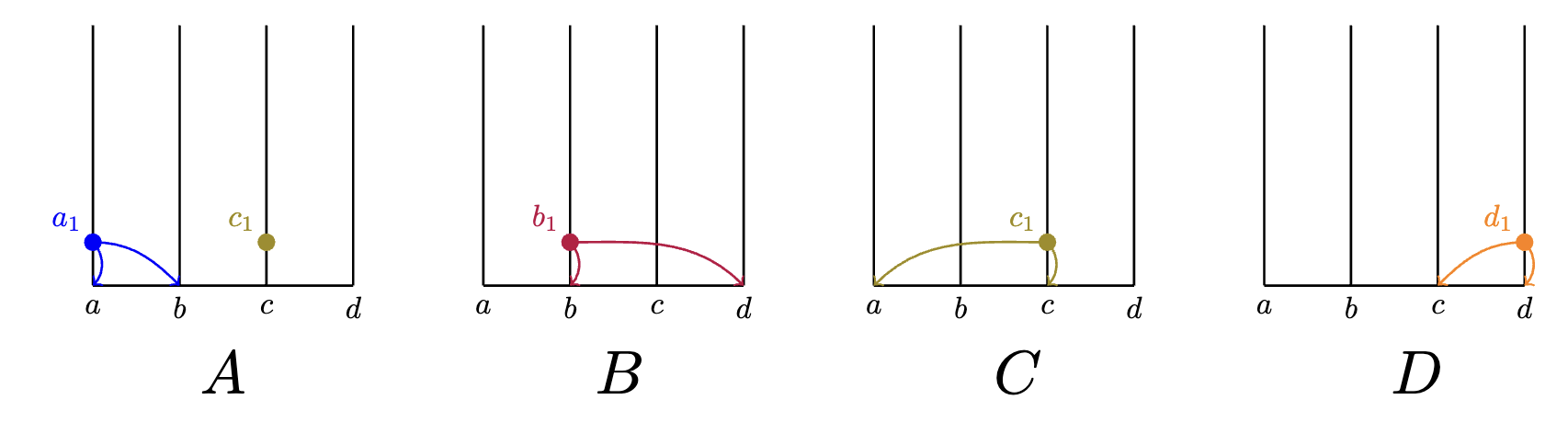
Immediately following receipt of , creates its own event which fathers .
Lemma: "fathering"


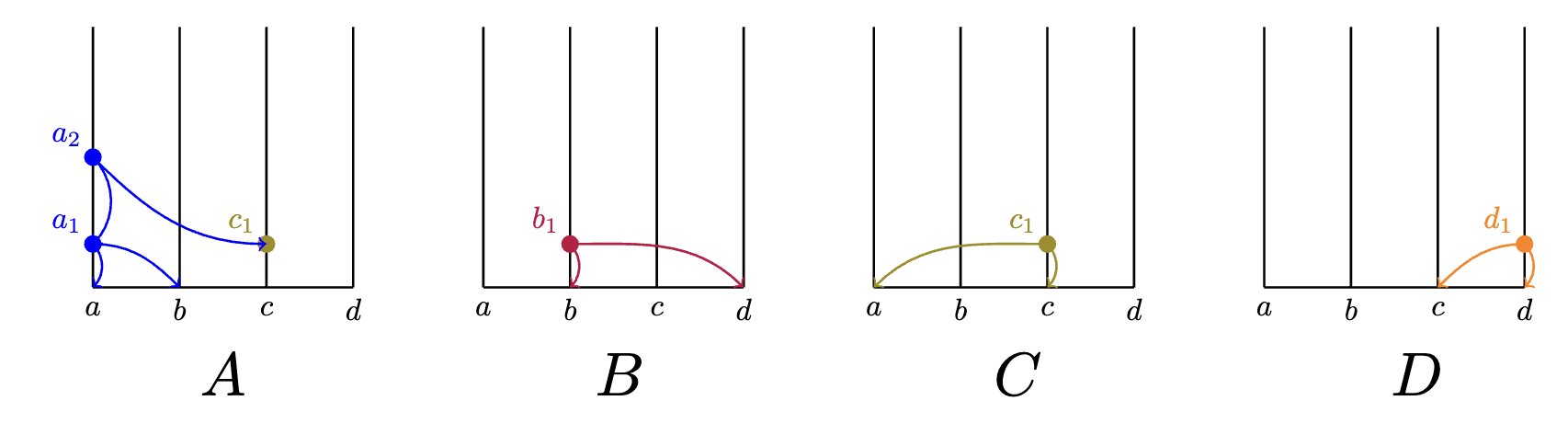
Imagine that, in the meantime, also receives event from . will sign a new transaction indicating receipt of and is ready to offer their new gossip to other members.
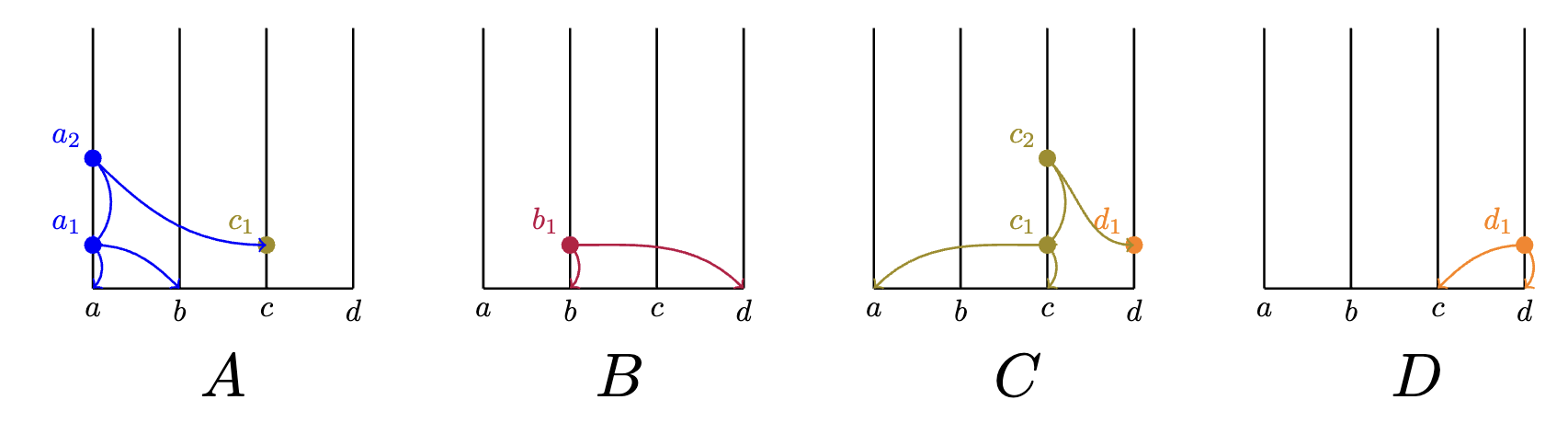
eventually, all nodes receive some events from one another such that the overall state of each member resembles the following:
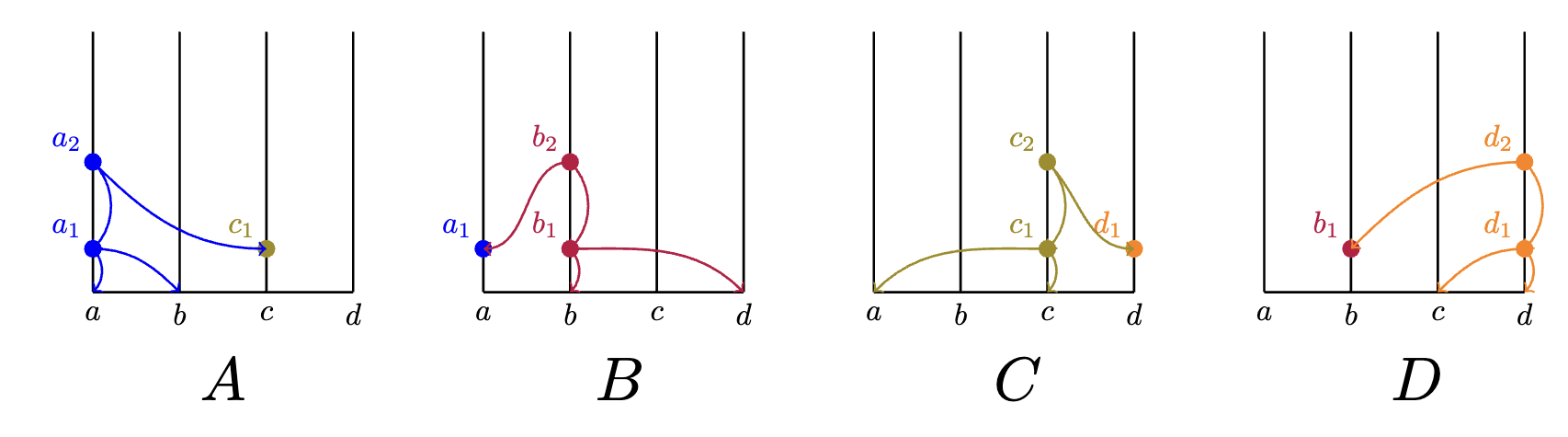
As the gossip about the gossip unfolds, each member's local copies of the HashGraph may not be identical. However, all events observed by a member will be recorded in their own copy.
A Random Exercise in Impermanence (The Collector)
(Exchange of Information)
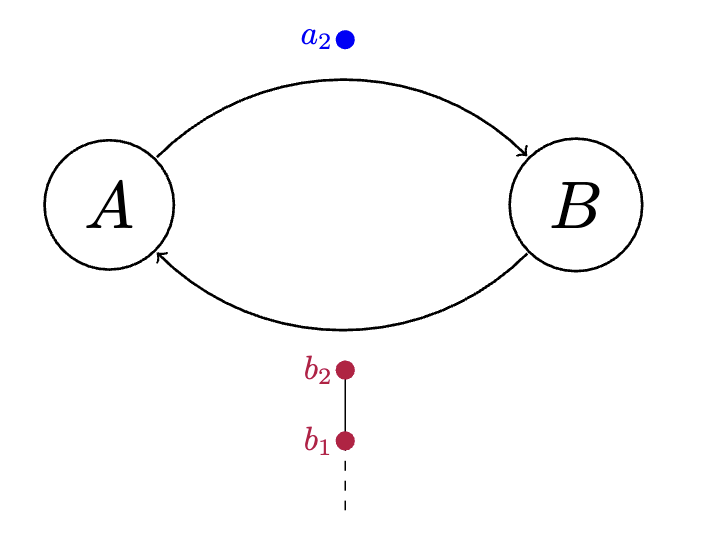
Recall that whenever a member broadcasts a synchronization update, the only information that need be exchanged (ignoring the accompanying signatures because the authors have thoroughly convinced the reader that you can pretty much send the size of that siggy to 0) is the delta between what member knows and what that member knows another member does not know.
Consider the final state of the previous example:
's next broadcast to will only include the new information that has and 's internal representation of does not, and vice versa. The actual delivery and receipt of the state diffs of different members of the hashgraph is as follows.

So that the resulting states of the involved members are:

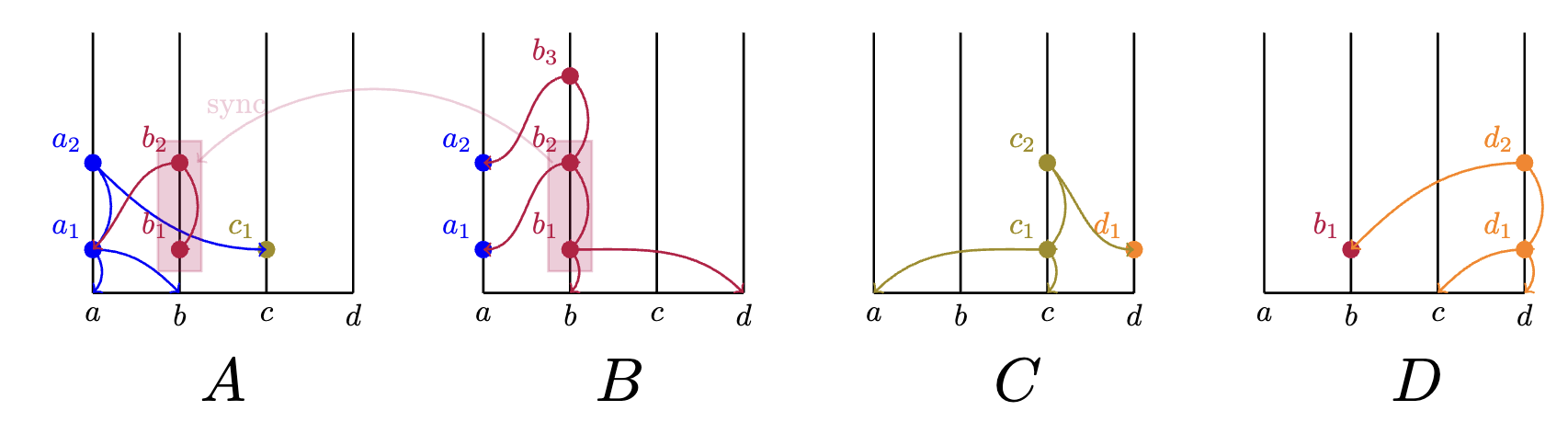
Bono!! Bono!!
(Conclusion)
So, that's that's pretty much it? Ended up with far more subsections than songs in the playlist, so forgive the deviation from form (some song titles are in fact relevant smh). What're you gonna do, vote about it?
c u in da ballpit
(Swirld's Functional Appendix)
| term/function | definition | description |
|---|---|---|
| an event tuple | ||
| the "payload" data, e.g. a list of transactions | ||
| list of hashes of the event's parents, starting with the self-parent | ||
| creator's claimed datetime of the event's creation | ||
| creator's ID | ||
| creator's digital signature of | ||
| the number of members in the HashGraph | ||
| the frequency of coin rounds | ||
| rounds delayed before start of deletion | ||
| the set of all events in the HashGraph | ||
| joined with the null message marker | ||
| the set of all possible pairs | ||
| the big natural: | ||
| set of events that are parents of | ||
| the self-parent of event , or if none | ||
| true if can reach by following or more parent edges | ||
| true if can reach by following or more selfParent edges | ||
| true if the set of events has more than events, and all have distincy creators | ||
| true if is an ancestor of , but no fork of is an ancestor of | ||
| true if can see events by more than creators, each of which sees y | ||
| the maximum created round of all parents of ? 1 if none | ||
| the created round of | ||
| true if has a greater created round than its selfParent | ||
| the number of votes equal to about the fame of witness collected by witness from the previous round | ||
| fraction of "ye" votes, regarding the fame of witness , collected by witness x$, from witnesses in the previous round | ||
| true if (or its self ancestor) "decided" for the elction for witness (and therefore that member will never change its vote about again) | ||
| true if should simply copy its selfParent's vote about the fame of witness (or is not a witness, or has already decided earlier) | ||
| the vote by witnes about the fame of witness (true for famous, false for not) | ||
| true if is famous (i.e., has had its fame decided by someone, and their vote was true) | ||
| true if is famous and is the only famous witness in that round by that creator | ||
| true if all known witnesses had their fame decided, for both round and all earlier rounds | ||
| the round received for event | ||
| the consensus timestamp for event |
Kawasaki Backflip
Footnotes
please please please someone start a blogging flame war with me. ↩
"Why Computers Can't Count Sometimes." The King, Tom Scott. ↩
Acceptable pronunciations include "credit", "Crudités", and "Kurds" ↩
Shapiro et al. "A comprehensive study of Convergent and Commutative Replicated Data Types." 2011. ↩
A join-semilattice is just a set that implements
Comparablewith a total ordering: , where is the greatest lower bound of ↩Fischer, Lynch, Paterson. "Impossibility of Distributed Consensus with One Faulty Process." Journal Association for Computing Machinery, 1985. ↩
Again, arbitrary domain, just needs to match the above. ↩
Baird, Leemon. "THE SWIRLDS HASHGRAPH CONSENSUS ALGORITHM: FAIR, FAST, BYZANTINE FAULT TOLERANCE." Swirlds. 2016. ↩
Though it seems like this would actually be an computation, where is the total number of transactions, as needs to traverse the HashGraph to find , the authors point out that for the purpose of sight (and other properties used in the proofs of tolerance) the number of temporally-prior nodes that any given node needs to view in order to "see" another node is actually negligibly small in terms of complexity. This sight need only look as far as the last Famous Witness which indicates that all transactions from rounds prior to that famous witness are agreed upon by the system on the whole. Therefore, the search space for is bounded by 1 round. ↩
Flash Boys by Michael Lewis is a great book about why even milliseconds of either inaccuracy or advantage in an exchange market can be hugely exploited by high frequency traders. ↩
It's worth noting that this point of contention is largely a theoretical one. Leader/follower-based consensus protocols are still prevalent in the industry and you don't see the world going up in flames about it. ↩