Digest: TrueSkill 2: Better Bayesian Assumptions Boogaloo
- Published on
- ∘ 12 min read ∘ ––– views
Tags
Previous Article
Next Article
Preface
This article contains my summary of Daniel's summary of Microsoft Research's publication 2018 "TrueSkill 2: An improved Bayesian skill rating system", an improvement on the original TrueSkill system developed for match making in Halo (3?, never played too much Halo 😬).
This paper was pretty straightforward, so this article will just cover the key points made in each section, focusing on the applications of Bayesian Networks and Markov Chains for Monte Carlo Methods.
Introduction
The paper aims to develop an accurate and computationally efficient skill rating to estimate the ability of a player to win the next match. In order to meet the requirements, set in place by the researchers for developers, the probabilistic generative models must make assumptions about how match results are related to player skill and vice versa. Furthermore, there are meta-requirements to make this rating accurate with minimal data as the alternative of playing dozens of matches before noticing improved math making would suck, and no one would play the game. Bayesian inference is good at approximation with few data.
"A system or model is only as good as its underlying assumptions."
Priorities for TrueSkill 2
- Support for team games
- Changeable skill ratings over time
- Compatibility with existing Match Making systems
- Aligned Incentives such that players seek to improve their skill rating by completing the objectives of the game, as an "optimally accurate" prediction model might be hackable e.g. quitting while ahead or camping to prevent deaths
- Minimal training data requirements
- Low computational cost: $
- Minimal tuning: time
Improvements on TrueSkill 1 (I refer to it explicitly TrueSkill 1 to distinguish from the focus of this paper)
- Latent (potential) skill is measured by performance which is a noisy sample of the former, based on individual contributions (kill rate, death rate, score, AND wins/losses) rather than simply the win/loss ratio
- Team Performance is a weighted sum of the performance of all the players
- this assumes linearity of skill, but it's okay for reasons covered later, namely tunable parameters
- If the performance of one team exceeds the performance of another by some margin , the that team wins
- A player's skill evolves over time according to a random walk which is biased towards improvement over time
- Quitting or leaving a match early matters
- Skills is assumed to be correlated across game modes, whereas TrueSkill 1 had independent parameters for different modes
- Players in a squad with one another are assumed to perform better than normal
Bayesian Networks
- Nodes in a Bayesian Network represent things that you believe to be true
- Directed connections indicate the probabilistic dependency between beliefs
- Though connections are causal in direction, this is only a soft indication as Bayes rule allows us to go both way across the diagram of the model

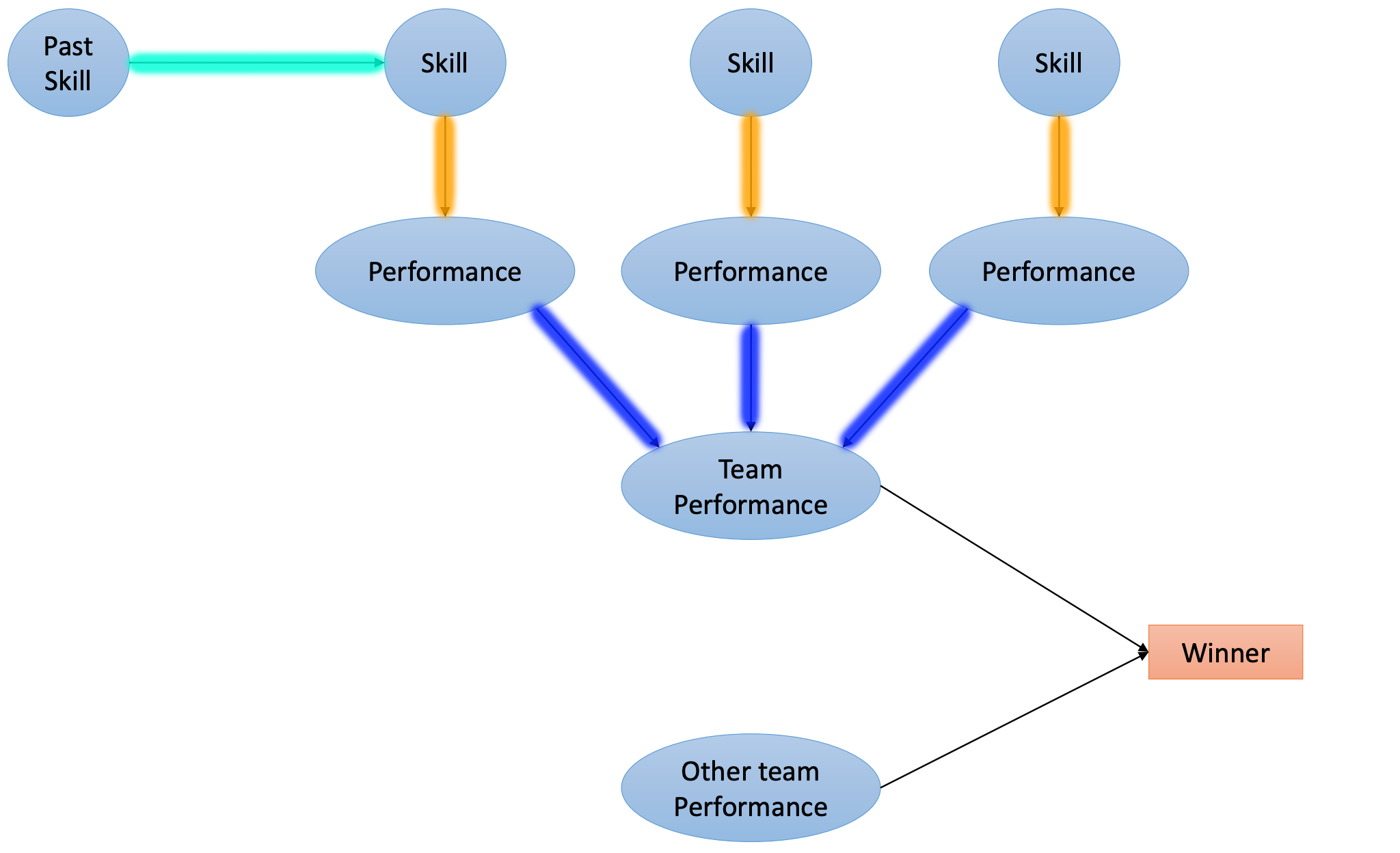
Building the Model
Base skill is defined by:
After each match, the player's latent skill changes by a random amount given by a variance parameter :
Degradation of skill over time spent not playing is given by a parameter :
And after each game, performance (sample of skill) changes by some amount related to the randomness of the game :
Simulated outcomes are intuitively defined as:
with overall team performance deterministically given as:
and team outcomes decided similarly.
Each of the parameters above are tunable, so the only assumption is that are given which should be available from a record of all or some prior games. Furthermore, using the Rule of 5, you could at least get the median (not to be naively confused with the mean).
| Tunable Parameter | Value |
|---|---|
| rating | |
| variance of the rating, the narrower the more accurate | |
| change in latent skill from game to game | |
| "rust" factor, account for not being warmed up & degradation of skill over time | |
| the amount of randomness in the game: difference between skill and performance | |
| the threshold for accurate results |
Markov Chain Monte Carlo Methods
If we know that and are normally distributed, it would make sense to assume that the model already suggests win/loss rate, but this is often not the case. Usually, these compositions of distributions are intractable, meaning they are not sample-able. Markov Chain Monte Carlo Methods let us work around this, with any such combination of distributions. If we follow the sample chain down to , we can roughly plot the resultant would-be sample of our intractable "winner" distribution. This plot would be numerically correct or accurate, but not analytically correct.
Computing Skill Ratings
Formally, the model defines a joint distribution over player skills and match results, conditional on the un-deled aspects of each match (which we will abbreviate as ):
In practice, we don't compute the entire joint distribution over , but only the marginal distribution of . This distribution is approximated by a Gaussian, and the mean of that Gaussian is taken as the player's skill rating.
Algorithm for computing skill ratings
TrueSkill 2 used online updates which were fast, real-time approximations of the resultant distribution over . The paper also discussed the increased accuracy of skill ratings from batch processing which was drastically slower, but less noisy. However, after a few sample games, the online ratings roughly converged to the batch-inferred ratings (this is how match making is able to provide relatively decent matchups in games like CS, or Rocket League after 10 qualifying matches )
Parameter Estimation
We can tune the aforementioned parameters until our model resembles historical data. They could be trained in a variety of ways, including evolutionary, or genetic methods. Using RProp which, among other things, only uses the signs of the gradients to compute updates.
Speculation: TrueSkill 2 uses RProp for its low computational cost and is potentially better suited for rocky training landscapes. Additionally, the standard backpropagation might not have tracked match outcomes as well as RProp.
With sufficient training data (1000 matches, for Halo 5: Slayer game mode), the following parameter values resulted in satisfactory model accuracy:
(team mates are very important)
(skills of new players on varied by ~1 from the mean)
(skills change slowly)
(draws are rare)
Metric-driven Modelling and Individual Statistics
"You find a way to measure the outcome you want, you offer to give someone access to levers by which they can plausibly influence this outcome, and you contract to pay them more cash the higher is this measure." - Rob Hanson
This section of the paper described how the research team achieved increased predictive accuracy by incentivizing or identifying individual metrics which contributed to .
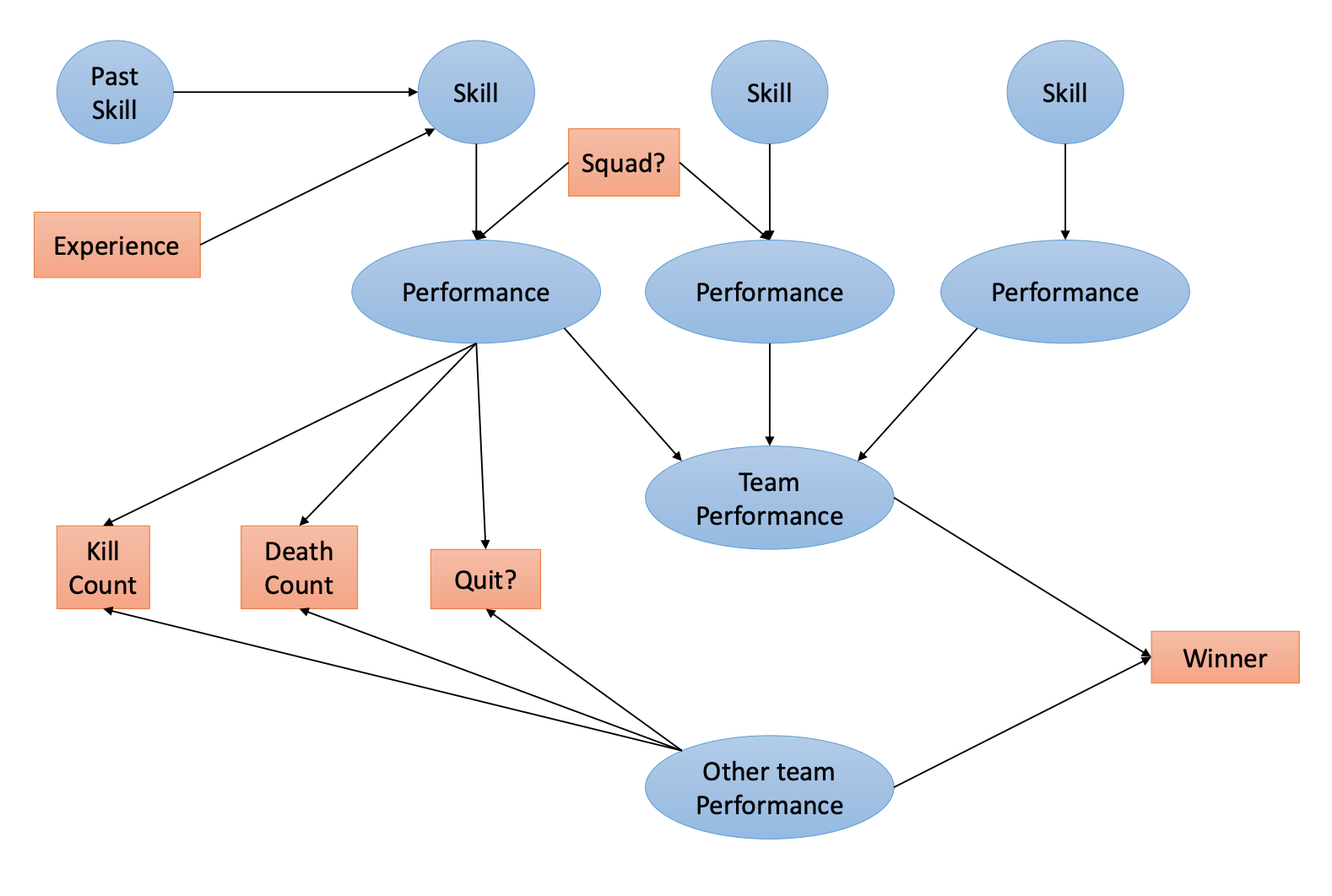
Squad Offset
Noting that when players queue together, they tend to have a higher , the model adds an offset to the depending on the size of the squad s.t.:
Experience Effects
In order to bias the change in with experience towards improvement, the team introduce a variable to be the number of matches played in the current game mode before time , capped at 200 for computationally efficient.
Additionally, other statistics that might have deserved their own modifications as above seemed to be strongly correlated with tracked parameters. For example, a lapse in time played was strongly correlated to kill rate and death rate, as was score.
Gamemode
By adding additional tunable parameters , for each count type for each game mode. the model was able to determine how individual statistics depend on performance, the skill of teammates, and opponents:
This model worked for any team size are is unique to previous work on sports scores in 3 ways:
TrueSkill 2 incorporates the effect of match length (and the penalty of leaving early)
TrueSkill 2 models correlation between individual statistics and a player's ability to win
TrueSkill 2 incorporates the effect of having many teams of different sizes
By delineating between and in a specific game mode, the model was also tunable per different modes s.t. the #1 free for all player doesn't get matched against the #1 player of a different game mode that he might suck at.
Adding in the additional assumptions defined for TrueSkill 2, the model now resembles:

Additional reading
Bayesian Methods for Hackers (the missing modeling manual for PyMC3)