Librarians, Luhn, and Lizard Brain
- Published on
- ∘ 65 min read ∘ ––– views
Previous Article
Next Article
'Cause a fear of disrepair can grow overblown and trite
And surely less sustainable than some ailment more defined
So give me tribulations, so give me trials
And errors, and errors, and errors, causes, and "whys?"
What in the...
I returned to an old textbook on Error Correcting Codes1 due to some bafflement caused by one of the explanations for the simple ISBN-10 algorithm for error detection and tripped and fell down a rabbit hole.


Pragmatically, the motivation for the algorithms discussed in this post centers around error detecting codes (but not correcting codes, unlike the Galois code covered in this post2 which goes into more depth on the nature of both types of codes and some of the requisite Group Theory basics I needed to grokk the Galois).
I stumbled across an arcane piece of code at work that employed a related algorithm to validate a debit card number before passing it along to a third party payment processing network since it's both faster and more affordable to attempt this on the "client" side before passing it along to e.g. Visa who could munge it over for hundreds of milliseconds before returning an error and an invoice t'boot.
In this post I'll briefly summarize:
- The ISBN-10 code
- The aforementioned Luhn algorithm widely used for computing a check-digit for debit cards
- A superior code developed (independently) by both Jacobus Verhoeff3 and Peter Gumm4 which detects more errors than Luhn's imperfect-but-simpler method
- This is where I'll spend most of the words (and symbols) allotted for this post, providing an alternate geometric interpretation of the proof(s) provided by the original authors
ISBN-10
Cumulative Sum of Digits
As mentioned, Todd Moon1 describes the International Standard Book Number as a sequence of digits† whose sum-of-the-sum of digits must be equal to and provides following tabular example of the confusing computation:
| digit | cum. sum | cum. sum of sum |
|---|---|---|
| 0 | 0 | 0 |
| 2 | 2 | 2 |
| 0 | 2 | 4 |
| 1 | 3 | 7 |
| 3 | 6 | 13 |
| 6 | 12 | 25 |
| 1 | 13 | 38 |
| 8 | 21 | 59 |
| 6 | 27 | 86 |
| 8 | 35 | 121 |
The final sum is .
† not restricted to strictly numerical digits since summation requires a digit to represent , so this code also employs the digit . The same method can be generalized to other bases as well such as alphanumeric sequences.
Weighted Sum of Digits
Conventional implementations of ISBN-10 describe a different process relying on a weighted single sum of the digits, assigning descending weights to each index:
for some minimum positive value of constrained by:
yielding an expression that indicates a valid check-digit is :
Curse the Senior Engineer and their Lizard Brains 🧠
It wasn't intuitively obvious at first how weighted modular arithmetic was equivalent to Moon's sum of a sum of digits, but we can observe that in the erstwhile cumulative summation, the first digit is accumulated in the sum 10 times, the 2nd digit 9 times, and so on – effectively weighting each digit according to its index in the same way the straightforward weighted summation does. Here's a sample implementation of the cumulative summation which neatly illustrated this property for me courtesy of the homie Will who's brain is sufficiently wrinkled to see the matrix:
def psychoDoubleCumSum(isbn: String): Int =
isbn.filter(_ != '-')
.map(_.toString.toInt)
.foldLeft((0, 0)) { case (acc, next) =>
val (middle, next) = acc
(middle + next, right + middle + next)
}._2
So, charged with the primitive ISBN-10 check-digit algorithm, we can approach the self-checkout at the library, and if a book (or any item) is scanned or otherwise processed for some arbitrary end, and it doesn't validate according to this check, we know that something's gone wrong. In the exempli bibliothecae, we're kind of just screwed (what're you gonna do, scan the book again 5head?), but there are myriad scenarios where error detection proves useful and where we might have more agency.
The Luhn Algorithm
Luhn's Algorithm is another basic modulo check-digit error detecting code developed by Hans Peter Luhn for IBM in 1960.5 At a high level, this algorithm works on a numerical sequence of length to generate an th check-digit by doubling every other digit, summing over the residual digits and adding the smallest positive value such that the resultant residual sum :
It is widely used to validate credit/debit card numbers (a scenario where a user might misread or fatfinger a digit).
For example, given hypothetical credit card with a Physical Account Number (PAN) of , we compute the following :
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 7 | 9 | 9 | 2 | 7 | 3 | 9 | 8 | 7 | 1 | |
| 7 | 9 | 7 | 9 | 7 | ||||||
| 7 | 9 | 7 | 9 | 7 |
Doubling every other digit, splitting those digits greater than 9 into two additional digits, and summing modulo ten we get:
It's worth noting that the implementation of modulo for negative number varies from language to language 🙃,6 so be careful and leverage associative operations to avoid the possibility of mistake. For example, we can instead prefer
performing modular summation before subtraction to guarantee that we avoid any zane (fairly assuming ). Associating operations to avoid calamity in this way will prove important later.
Shortcomings of the Luhn Algorithm
I once again refer back to my lengthier post about Error Correcting Codes which details more properties of such codes, but to summarize – Luhn's code detects:
- All single digit errors
- Most –but not all– adjacent transpositions provided one of the numbers involved isn't zero
- This "most" here is the crux of this post. Verhoeff set out to obliterate all missed adjacent transposition errors
Examples
As we can see, the Luhn code is susceptible to missing transpositions involving a 0-digit:
Let , and an erroneous transposition of be . The every-other-digit-doubled versions of these strings will be:
which means that a payment request in the common example of credit card validation will fail after hundreds/thousands of milliseconds rather than a dozen or so for the non-edge cases of transposition errors. Good thing "0" and "9" are nowhere near on the keyboard 🙃.7
In his own derivation of a superior check-digit generation technique, Gumm notes that:
Various check-digit methods have been designed for the decimal number system. Each method is able to detect all "single-error mistakes," but they fail to detect all transposition errors. At least one (and often not more than one) erroneous transposition is undetectable with those methods.
Errors
To motivate his own publication (which is really just an blog post peer reviewed gatekept by the establishment if you think about it), Verhoeff researched the frequency and category of all the types of errors which can occur in a code. Verhoeff identified the following types of errors:
- transcription: a straight up typo
- i.e. "Peter Gumm" -> "🅱️eter Gumm"
- transposition: two or more digits swapping positions
- i.e. "Peter Gumm" -> "Geter Pumm"
- twin transcription errors: a double fatfinger
- i.e. "Peter Gumm" -> "Peter Gunn"
- jump transpositions: a transposition of non-adjacent letters
- i.e. "Peter Gumm" -> "Peter muGm"
- phonetic errors: using a prohibited character
- i.e. "Peter Gumm" -> "Peter Gu44" (assuming a strictly alphabetic domain)
- jump twin errors: non-adjacent double typos
- i.e. "Peter Gumm" -> "Patar Gumm"
As well as their observed frequencies in real life scenarios:
| digits in error | error class | frequency (%) |
|---|---|---|
| 1 | transcription | 79.05 |
| 2 | transpositions | 10.21 |
| 2 | twins | 0.55 |
| 2 | phonetic | 0.49 |
| 2 | other adjacent | 1.92 |
| 2 | jump transpositions | 0.82 |
| 2 | jump twins | 0.29 |
| 2 | other jumps | 0.36 |
| 2 | other | 0.81 |
| 3 | (errors of the dyslexic variety) | 1.40 |
| 4 | bruh | 0.97 |
| 5 | BRUH | 1.81 |
| 6 | BRUHHHH | 1.34 |
From this table, we can see how Gumm is able to make the at first lofty-seeming claim that every single-error check-digit code immediately detects about 90% of all format errors, since about 90% of common errors are either single digit transcriptions (~80%) or mundane transpositions (~10%) for which – of the two digits, one will necessarily be detected.
Relying on Verhoeff's research which showed that the vast majority of real errors are effectively detected by Luhn's algorithm, Gumm also notes that –despite how tempting it may be to just tack on additional check-digits to capture the remaining 2% of transposition errors–
The use of two check-digits ... is not advised since the previously mentioned studies have also shown that the absolute number of errors that occur roughly doubles when the number of digits increases by two. ... We therefore concentrate on methods to detect single-digit errors and transposition errors.
That is – each additional check-digit increases the literal and statistical surface area for a fatfingered input.
Gumm asserts that all error detecting codes of the form are flawed for this reason.
Criteria for an Improved Error Detecting Code
Gumm introduces the following preqrequisites for an improved check-digit code. Borrowing his notation which I'll discard shortly, he defines a check-digit method base as a set with together with a family of operations . An operation on the elements is interpreted as the check-digit for a number with decimal representation in base . To improve on methods, the following axioms must satisfied for all :
Axiom 1: Typos are Detected
If the check-digit calculation is identical for two sequences involving , then the two "differing" digits must be not actually be different. This axiom guarantees single-error detection.
Axiom 2: Transpositions are Detected
If two digits are transposed, and the check-digit remains equivalent, then the two digits must be identical.
Axiom 3: Transpositions Involving the Check-Digit and its Left Neightbor Are Still Detected
The Verhoeff-Gumm Algorithm
With these criteria in mind, Verhoeff and Gumm both sought out to develop a better code which could detect 100% of all single-digit and transposition errors. Verhoeff proved the existence of such a code, and Gumm provided a concrete permutation of digits in the Dihedral Group of order 10 () which satisfy these criteria. Let's take a look at how we might go about trying to do the same. We'll use a simple 4-digit example throughout: and determine a means of generating a 5th digit such that the whole code is impervious to the two aforementioned classes of errors.
Looking at the arithmetic toolbox, we might reach for simple operations such as addition, subtraction, multiplication, or division. However, by themselves, each of these operations fails for either single-digit or transposition errors, or both (lookin' at you division):
| operation / error | code | detected? |
|---|---|---|
single-digit | ✅ | |
transposition | ❌ addition is commutative | |
single-digit | ✅ | |
transposition | ❌ multiplication is commutative | |
single-digit | ✅ | |
transposition | ❌ subtraction is commutative† | |
single-digit | ✅ but bad in general since we'd like | |
transposition | not even gonna bother |
† subtraction fails to detect transposition errors unless a distinct, adjacent pair not including the leading digit is transposed: e.g.
which is a false negative!
Consider: the Square
So, we'll have to plumb the depths of our operations for something less trivial. Let's reach for geometry. Consider the square and the things we can do to it.
If we take a square, we can rotate it counter clockwise about its center by 90º yielding a new square:
we can also flip it along its vertical axis yielding yet another new square:
What happens if we flip first, then rotate?
BAHA yet another new square – like a caveman discovering fire, we've defined two non-commutative, primitive operations on our square: and . From these, we can get 8 distinct squares:
- : 0: our arbitrarily chosen progenitor
- : 1: one 90º rotation from
- : 2: two 90º rotations from
- : 3: three 90º rotations from (note that four 90º rotations from is )
- : 4: flipped about its vertical axis
- : 5: flipped about its vertical axis
- : 6: flipped about its vertical axis
- : 7: flipped about its vertical axis
Each square can also be thought of as an operation rather than just the element, with being the identitive element (a 0º rotation with no flips leaves any square unchanged), being a single rotation (I'll drop the directional notation since a -90º rotation is equivalent to three +90º degree rotations which is , so if we ever wanted to perform, say, an we'd instead do ), and each of the flips are just combinations of some amount of rotations before flipping about the axis (implicitly the vertical axis since we can make the horizontal axis the vertical axis via rotation).
Using our Square, we can potentially map 8 distinct digits to our arrangements of the Square which are formed by non-commutative primitive operations. However, modern society (since the 7th century Indian Vedic mathematicians pioneered the base 10 system commonly used today) has embraced a decimal system rather than an octal system (and even then, sometimes 10 digits still ain't enough, see ISBN-10, and written language, and the languid existence of culture), so we're going to need a couple more squares...
Consider: The Pentagon
Luckily, we can also generalize our same primitive operations to the Pentagon, which has 5 distinct rotations of 72º each, and 5 axes of symmetry, which conveniently gives us 10 arrangements (See the Appendix on for more details).
Define the elements of our set of Pentagons (which I'll refer to as for no reason in particular😈) to be the following:
- : 0: an arbitrarily chosen, promethean identitive element from which we'll anchor the definitions of all our other Pentagons
- : 1: the 1st rotation by 72º
- : 2: the 2nd rotation by 144º
- : 3: the 3rd rotation by 216º
- : 4: the 4th rotation by 288º
- : 5: the 1st flip, along the blue/red axis (axis 1) of
- : 6: the 2nd flip, along the yellow/green axis (axis 2) of
- : 7: the 3rd flip, along the red/orange axis (axis 3) of
- : 8: the 4th flip, along the green/blue axis (axis 4) of
- : 9: the 5th flip, along the orange/yellow axis (axis 5) of
We can interpret each pentagon as a digit according to its index subscript.
How to use it tho?
Returning to our example string of for which we still desperately need a check-digit and interpretting it as a sequence of pentagons, we get
But even armed with the knowledge that our Shapes themselves can be interpreted as operations, how are we to combine them with either operation?
Composition
Composition babyyyy! We can treat each Pentagon as a simple algebraic composition of functions akin to :
In general, Group Theoretic operations compose from right to left. The Pentagonal analog for a Luhnean check-digit is whatever Pentagon we start the chain of operations on (so, still the rightmost digit) that results in
So what Pentagon can we prepend the composition with such that our result is ?
Computing a Pentagonal Check-Digit
Though our family of operations isn't commutative, it is associative, so we can group the operations with parentheses however we please. Knowing that a sequence of Pentagons is equivalent to the composition of operations on a starting Pentagon, and that each operation is itself a Pentagon, we can group and reduce our previous equation:
We introduce the inverse of to find the Pentagon corresponding to our check-digit:
Intuitively, the inverse of of is since that's 5 rotations == 0 rotations, so our check-digit is .
We can verify this mechanism is resistant to transposition by swapping operations to see that the result of composing is no longer :
Can we prove this works in general though? Or are there any edge cases (like adjacent 0,9 Pentagons that would cause trouble as in Luhn's algorithm?) for which we might accidentally wind up with a false positive green flag .
Proving Pentagonal Correctness
We can verify with a tabular illustration of all mappings of Pentagons to their corresponding elements under each operation – this is known as a Cayley Table.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | 1 | 2 | 3 | 4 | 0 | 6 | 7 | 8 | 9 | 5 |
| 2 | 2 | 3 | 4 | 0 | 1 | 7 | 8 | 9 | 5 | 6 |
| 3 | 3 | 4 | 0 | 1 | 2 | 8 | 9 | 5 | 6 | 7 |
| 4 | 4 | 0 | 1 | 2 | 3 | 9 | 5 | 6 | 7 | 8 |
| 5 | 5 | 9 | 8 | 7 | 6 | 0 | 4 | 3 | 2 | 1 |
| 6 | 6 | 5 | 9 | 8 | 7 | 1 | 0 | 4 | 3 | 2 |
| 7 | 7 | 6 | 5 | 9 | 8 | 2 | 1 | 0 | 4 | 3 |
| 8 | 8 | 7 | 6 | 5 | 9 | 3 | 2 | 1 | 0 | 4 |
| 9 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
which looks like troglodytic vomit. A heatmap is easier to digest:
Cayley Tables are useful since they remove the need for guess and checking (or thinking whatsoever) about inverse operations: cells with entries indicate inverses. Additionally, we can detect transpositions by noting that e.g.
If we fold the whole table along the major diagonal, we can note that most of the table has asymmetric results (highlighted in green), indicating that transpositions produce different check-digits (you're gonna have to flip your phone sideways for this one – sorry not sorry):
Alternatively, here's an image for mobile plebians.


The non-green cells are symmetric entries indicating undetected transpositions e.g. . In general, any combination of two rotations, or any operation with the identity has an insecured symmetry.
Blasted Symmetries
We can circumvent these blind spots by adding a pre-processing step to introduce further asymmetry across the table, just like how the Luhn algorithm doubles every other digit before summation, and ISBN utilizes index weights. We'll call our asymmetric "activation function" .
We'll apply to pairs of Pentagons that are about to be combined. We need to define our s.t. for pairs appearing in a sequence:
Implying that should produce a different check-digit for two sequence differing by a transposition.
To prove this property, we have to deviate from our colorful geometric fantasy land of Pentagons, and instead model our elements as germane integer tuples (this is how is conventionally tracted). Each Pentagon can be uniquely described by a tuple of the form:
where negative indicates a flip, and indicates how many rotations have been applied to . Our new exhaustive list of Pentagons is:
We combine tupled Pentagons according to the formula:
which checks out according to our Cayley Table! Note that we constrain our arithmetic to bound the number of rotations to the number of smmetrical axes in our polygon (where get the name). With our new (gross) algebraic model of our Pentagons, we can devise a .
Bad Sigma
Intuitively, we might just try adding some constant and see if that works, or at least how it behaves:
To verify, we just have to show that this sigma function detects transpositions:
We know that for all values since arithmetic multiplication is commutative, so that will cancel the first element from both sides, leaving us to examine the second:
Breaking the remaining possibilities out into cases:
⚔️ well shucks, looks like adding a constant produces a contradiction right away – back to the drawing board.
Gud Sigma
A better posited by Gumm is:
Geometrically, we can interpret this to mean
Proof
Again, only having to consider the second term of each tuple:
we have two cases:
Case 1 is always true since we require , and case 2 is only true if which is by definition not a transposition, so it's always true.
By choosing some fixed , we can pre-compute a table of permutations of the elements of like the following:
Does this technique scale to more than one transposition/more than two elements?
Yes! If we prove that applying to the 2nd digit rather than the 1st also holds for our transposition property, then we can borrow the preprocessing pattern from Luhn and apply to every other element in a sequence. E.g.
Leveraging the associativity of our group operation, we can ~group~ some terms to conveniently ~do something tbd to them~
Next, we'll introduce inverses to start deleting our problems.
Being extra tricky, since we can't introduce an inverse nor into the middle of either side, we'll simply apply the sigma function on the last term on each side, yielding some , and then we'll append (brackets added for readability) to both sides:
which leaves us with the very case that we have already proven for which will indicate a transposition.
The Complete Verhoeff-Gumm Algorithm
- Permute the digits† in our sequence according to our permutation function/table :
- Map the digits to their corresponding Pentagons/elements in :
- Combine
- Find/lookup = according to the precomputed Cayley Table and append the inverse of the result to the end
† I opted to permute every other digit, similar to Luhn, however this deviates from the proposed permutations of the original authors. Verhoeff's version of the algorithm applied once per index:
And Gumm (a known ISBN shill) applied once per index in reverse order:
Conclusion
Gumm's version is slightly superior since it allows for any amount of leading 0s in the sequence without throwing off the check, but if you're a credit card issuer minting cards with several leading zeroes, YTA.
Both methods account for the remaining ~2% of transposition errors that Luhn's algorithm overlooks.
In pursuit of Mentat medulla oblongata8, Cartesian Set-Set9 Synapses, or just good ol' brain candy, this visualization of the proof is just some good stuff.


Appendix: Taxonomy of

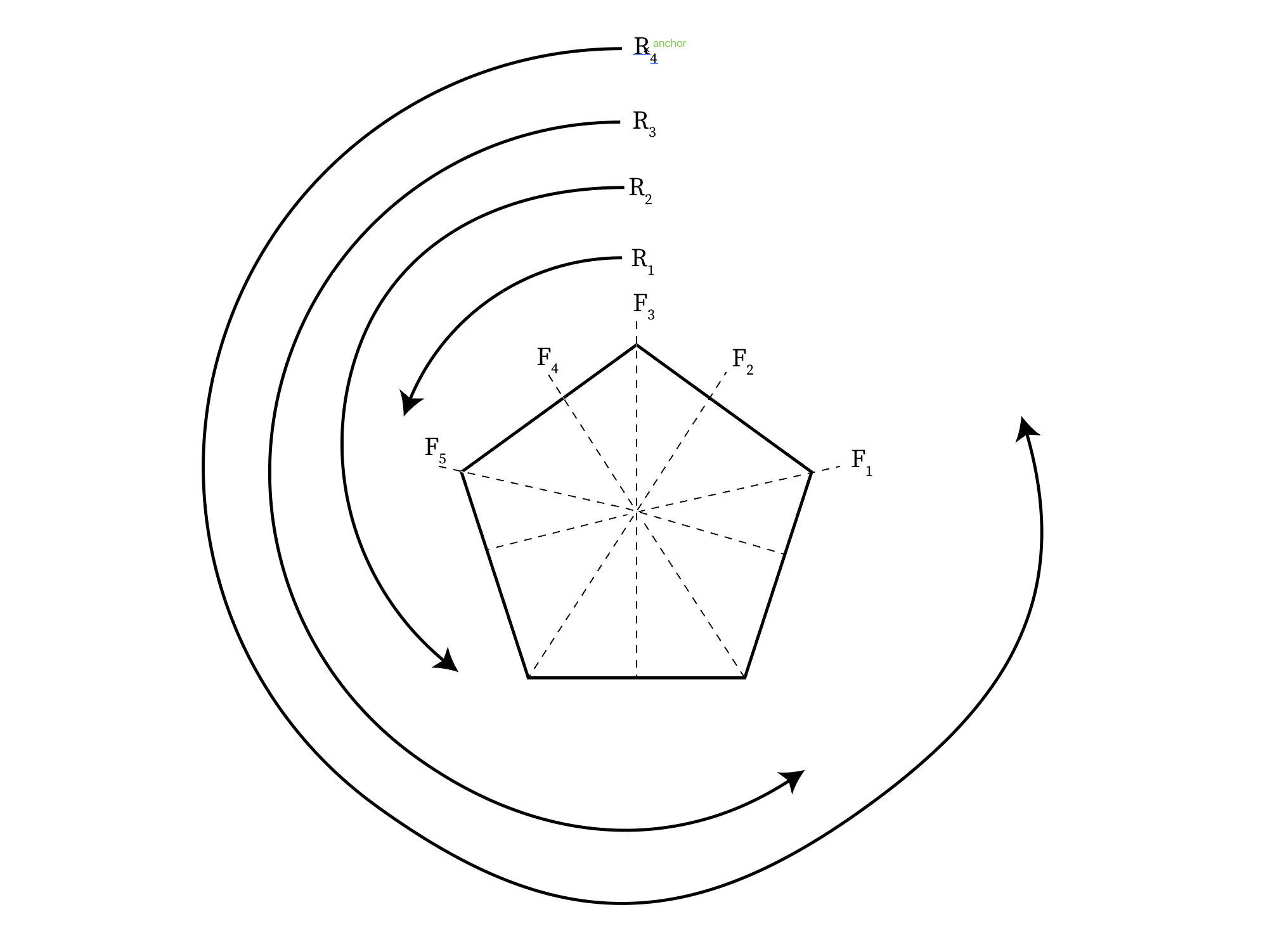
has 10 elements:
- An Identity: (or )
- 4 rotations:
- 5 reflections:
It can also be interpreted as a graph:

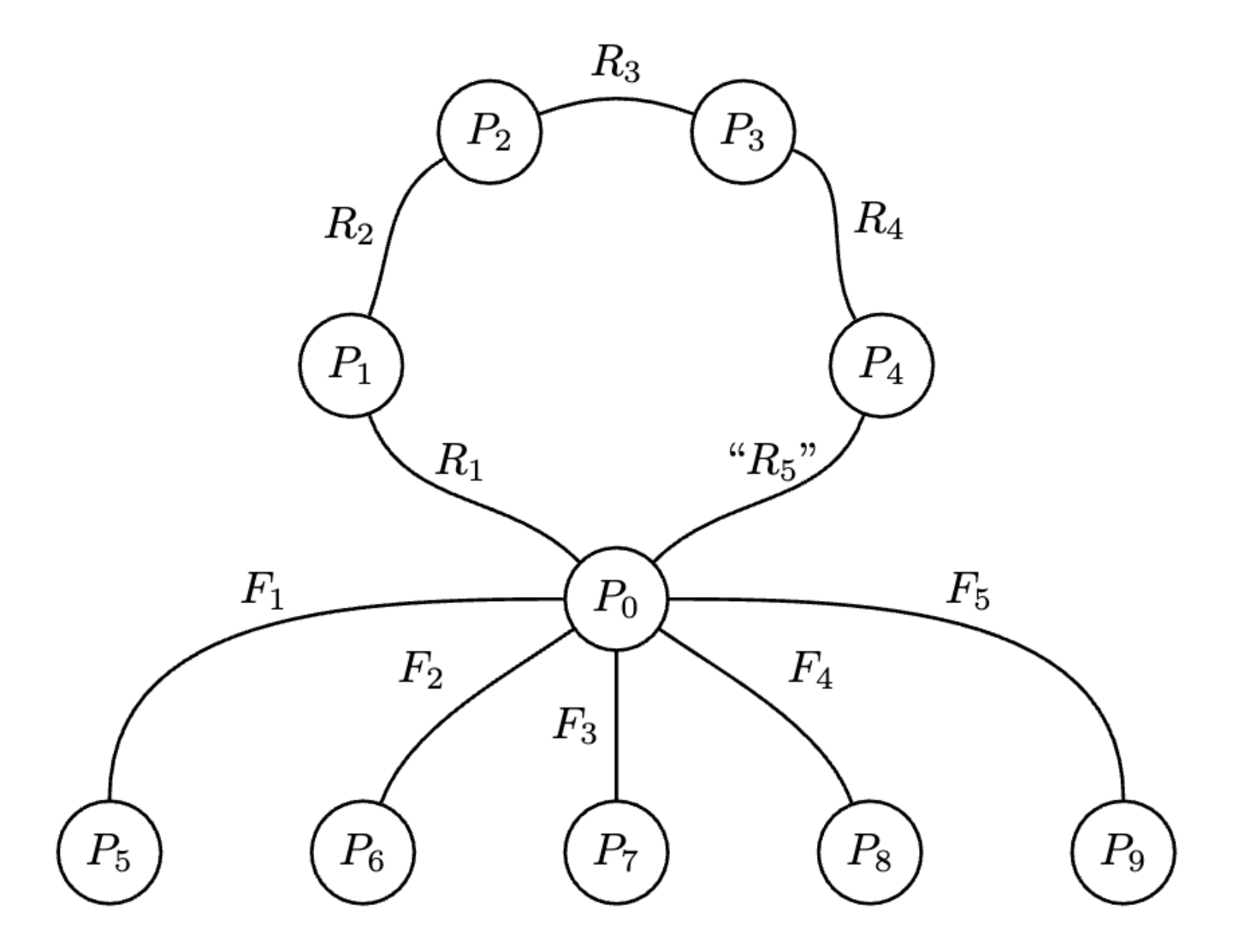
where edges are bidirectional, with the back-edge imlicitly being the inverse of the labeled forward-edge.
Or, more comprehensively:

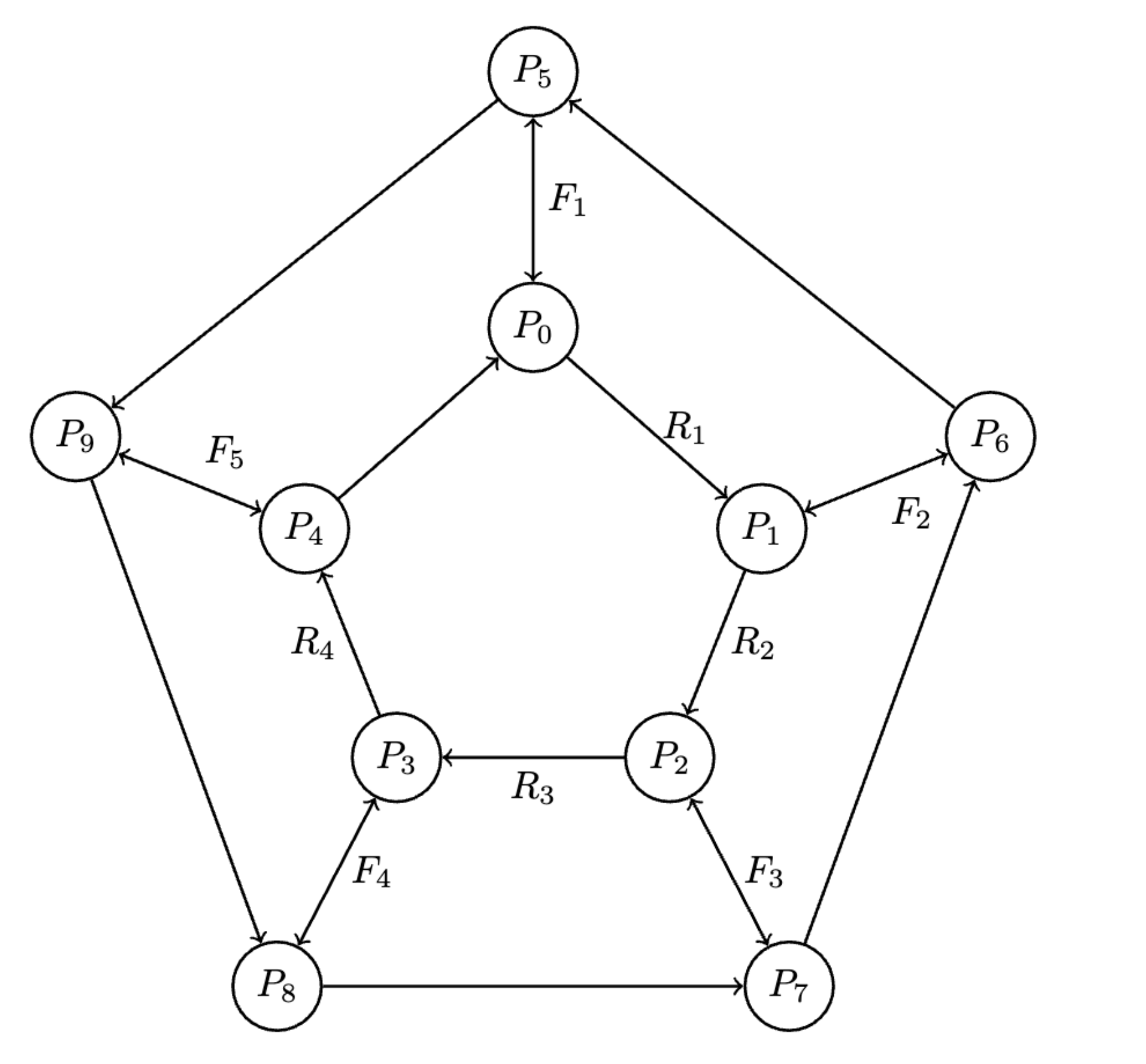
Footnotes
Footnotes
Error Correction Coding: Mathematical Methods and Algorithms, Todd Moon ↩ ↩2
Verhoeff, Jacobus. "Error Detecting Decimal Codes." Mathematical Centre Tracts, 118 S. Amsterdam, 1969. ↩
Gumm, Peter. "A new class of check-digit methods for arbitrary number systems." IEEE Transactions on Information Theory, 31(1). 1985. ↩
Patent granted on August 23rd, 1960, nearly 43 years to the day after I started delving into Verhoeff's algorithm – just in time to observe the anniversary by celebrating its theoretical obsolescence (though Luhn's algorithm is *cough* clearly still used in the industry today) ↩
https://torstencurdt.com/tech/posts/modulo-of-negative-numbers/ ↩
On keypads designed for entering numeric digits, "0" and "9" are usually separated for this very reason (amongst others) ↩
Palmer's "Set-sets" ↩